ToaSt: ViT를 더 가볍고 더 정확하게 만드는 분리형 압축 (ICML2026)

ToaSt 논문이 AI 분야 최고 권위 학회 중 하나인 ICML 2026에 채택되었습니다.
Vision Transformer(ViT)는 분류, 검출, 분할, 멀티모달 백본까지 폭넓게 쓰이지만, 높은 계산량 때문에 실제 배포 단계에서 병목이 자주 발생합니다. 이번 글에서는 ICML 2026에 채택된 ToaSt 논문의 문제의식, 방법론, 실험 결과를 논문 구조에 맞춰 자세히 정리합니다.
ToaSt의 핵심은 아래 한 줄로 요약할 수 있습니다.
- MHSA와 FFN을 분리해 각각 다른 전략으로 압축하고, 레이어 간 전파 문제를 피하면서 정확도-효율 균형을 동시에 개선한다.
1. 문제 배경: ViT는 어디서 느려지는가?
ViT 계산량은 크게 두 축에서 발생합니다.
- Attention: 토큰 수 (N)에 대해 대략 (O(N^2))
- FFN: 채널 차원 (D) 중심의 큰 연산량
논문에서 인용한 분석에 따르면 표준 ViT에서 FFN이 전체 FLOPs의 약 61%, Attention이 약 19%를 차지합니다. 즉 attention만 줄여서는 전체 효율을 충분히 끌어올리기 어렵고, FFN 중복을 직접 다뤄야 합니다.
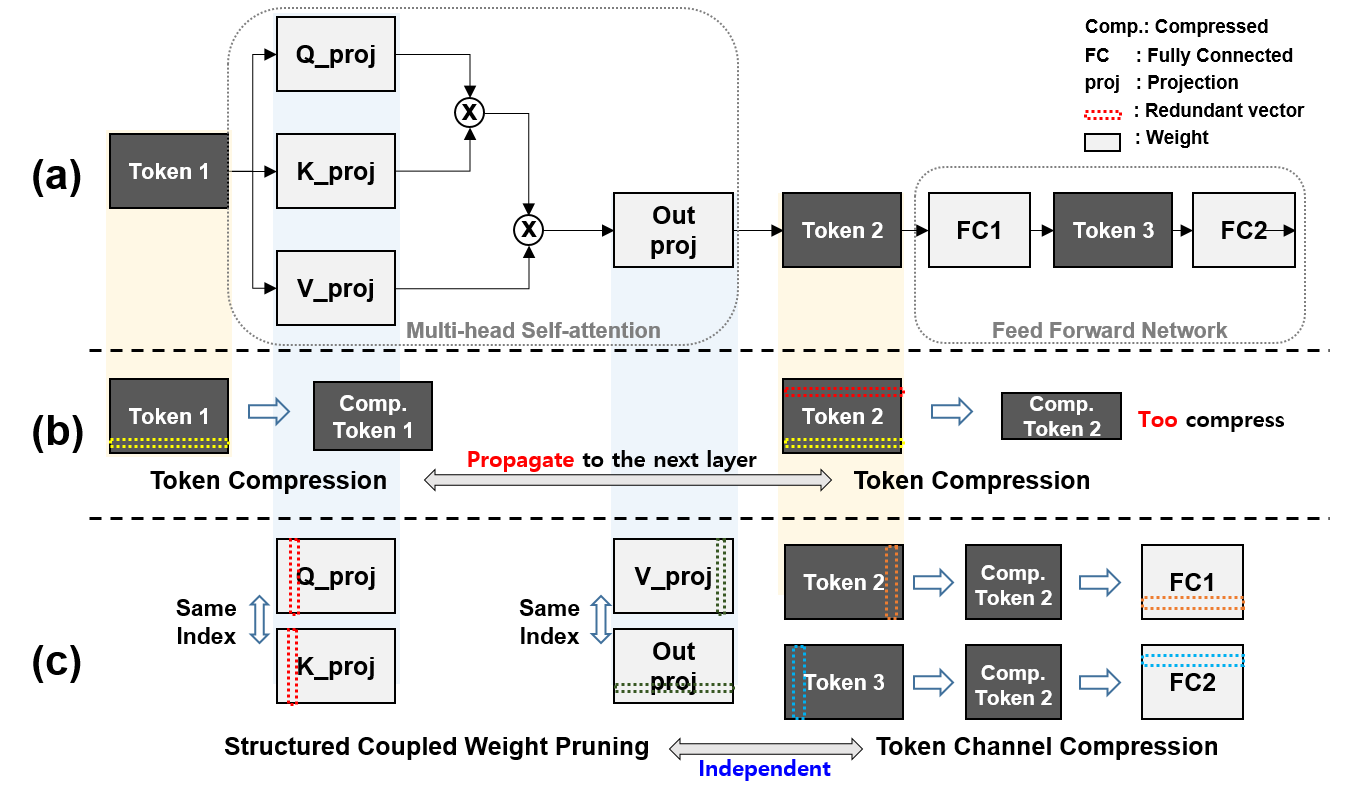
Figure 1. ToaSt는 MHSA와 FFN을 분리 압축해 레이어 간 전파 문제를 줄인다.
2. 기존 접근의 한계: 왜 새로운 설계가 필요했나?
논문은 기존 ViT 경량화 방법을 크게 세 그룹으로 정리합니다.
2.1 Structured Weight Pruning
- 장점: 채널/헤드/블록 단위로 잘라서 일반 GPU에서도 가속 가능
- 한계: 정확도 회복을 위한 재학습 비용이 큼
- 실제 문제: ViT 계열은 원래 학습도 길어(수백 epoch), pruning 후 긴 fine-tuning이 실무에서 부담
2.2 Token Compression / Token Merging
- 장점: (N)을 줄여 attention의 (O(N^2)) 비용을 직접 줄임
- 한계 1: FFN의 (D^2) 지배 항을 직접 줄이지 못함
- 한계 2: 한 레이어의 token 선택이 이후 레이어로 전파되어 전역 의존성이 생김
2.3 Joint / Hybrid Methods
- 장점: 여러 축을 동시에 최적화해 큰 가속 잠재력
- 한계: 최적화 공간이 복잡하고 설정 민감도가 높음
- 일부 방식은 하드웨어/커널 의존성이 커 범용 배포가 어렵기도 함
ToaSt는 이 지점에서 "한 번에 다 최적화"가 아니라 "모듈별로 분리해 단순하고 안정적으로 압축"하는 철학을 택합니다.
3. ToaSt 방법론: Layer-Independent Compression
ToaSt는 Transformer block의 입출력 인터페이스 ((N \times D))를 유지한 채, 블록 내부만 줄입니다. 이렇게 하면 앞 레이어의 압축 결정이 뒤 레이어로 강하게 전파되는 문제를 줄일 수 있습니다.
3.1 MHSA: Coupled Structured Pruning
MHSA에서 Q, K, V, Proj는 수학적으로 서로 연결돼 있습니다. ToaSt는 이 연결성을 무시하지 않고, 인덱스를 동기화해 함�께 pruning합니다.
- Q-K 동기화 pruning
- V-Proj 동기화 pruning
- 헤드 내부 차원 (d_k) 축소, 전역 임베딩 차원 (D) 인터페이스는 유지
중요도는 Geometric Median 기반 기준으로 계산하고, 작은 모델을 제외한 대부분 설정에서 첫 레이어를 보존한 채 나머지 레이어에 높은 pruning 비율을 적용합니다. 논문은 비정렬 pruning(non-align) 대비 정렬 pruning(align)이 고 pruning ratio에서 정확도 붕괴를 크게 줄인다고 보고합니다.
3.2 FFN: Token Channel Selection (TCS)
FFN은 (D \rightarrow 4D \rightarrow D) 구조를 갖고, 전체 연산량 비중이 큽니다. ToaSt는 FFN에 대해 학습 없는 동적 채널 선택(TCS)을 적용합니다.
논문에서 제시한 FFN 분석의 핵심 관찰은 3가지입니다.
- 깊은 레이어로 갈수록 활성값 sparsity 증가
- effective rank 붕괴(실질 표현 차원 축소)
- 높은 (R^2) 재구성(채널 간 선형 중복 큼)
이 관찰을 바탕으로 TCS는 토큰 일부를 샘플링해 채널 중요도를 추정하고, 중요 채널만 남깁니다. 중요도 계산은 CLS 전역 정보와 patch saliency를 결합한 형태이며, CLS가 없는 Swin 계열에는 patch 기반 항만 사용합니다.
또한 FC1(확장부)은 보수적으로, FC2(축소부)는 더 공격적으로 적용하는 비대칭 정책을 사용합니다. 논문 설정에서는 FC2 깊은 레이어에서 최대 90%까지 pruning을 적용합니다.
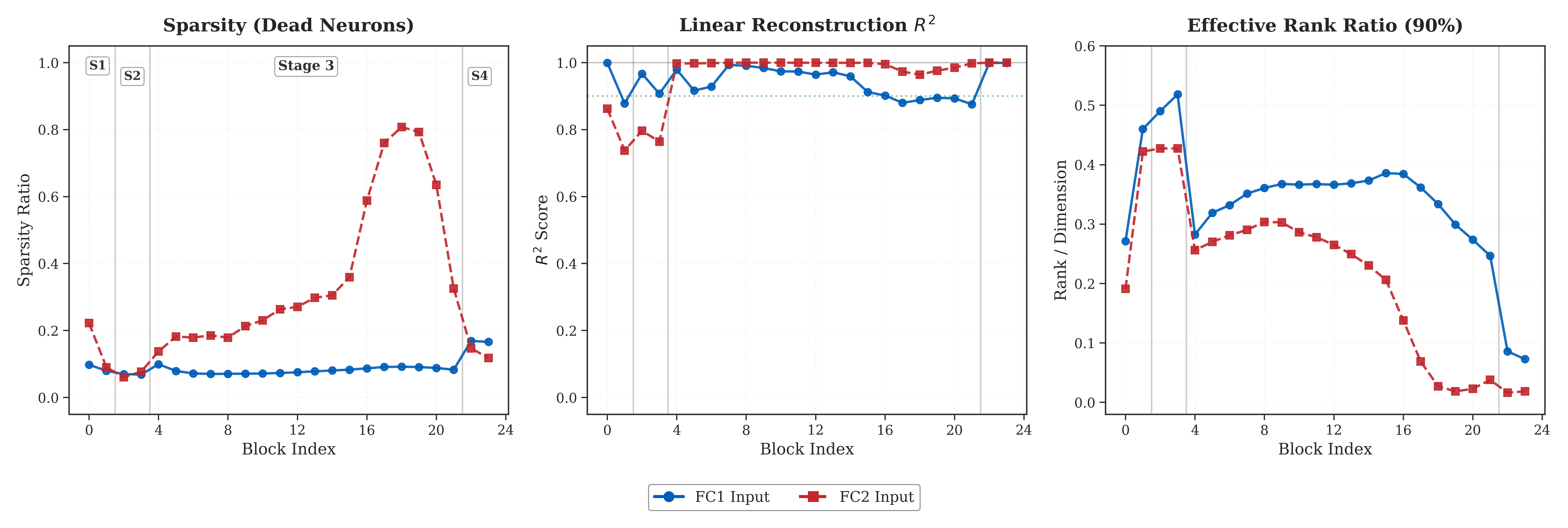
Figure 2. Swin-Base FFN 분석: 깊은 레이어일수록 중복이 커진다.
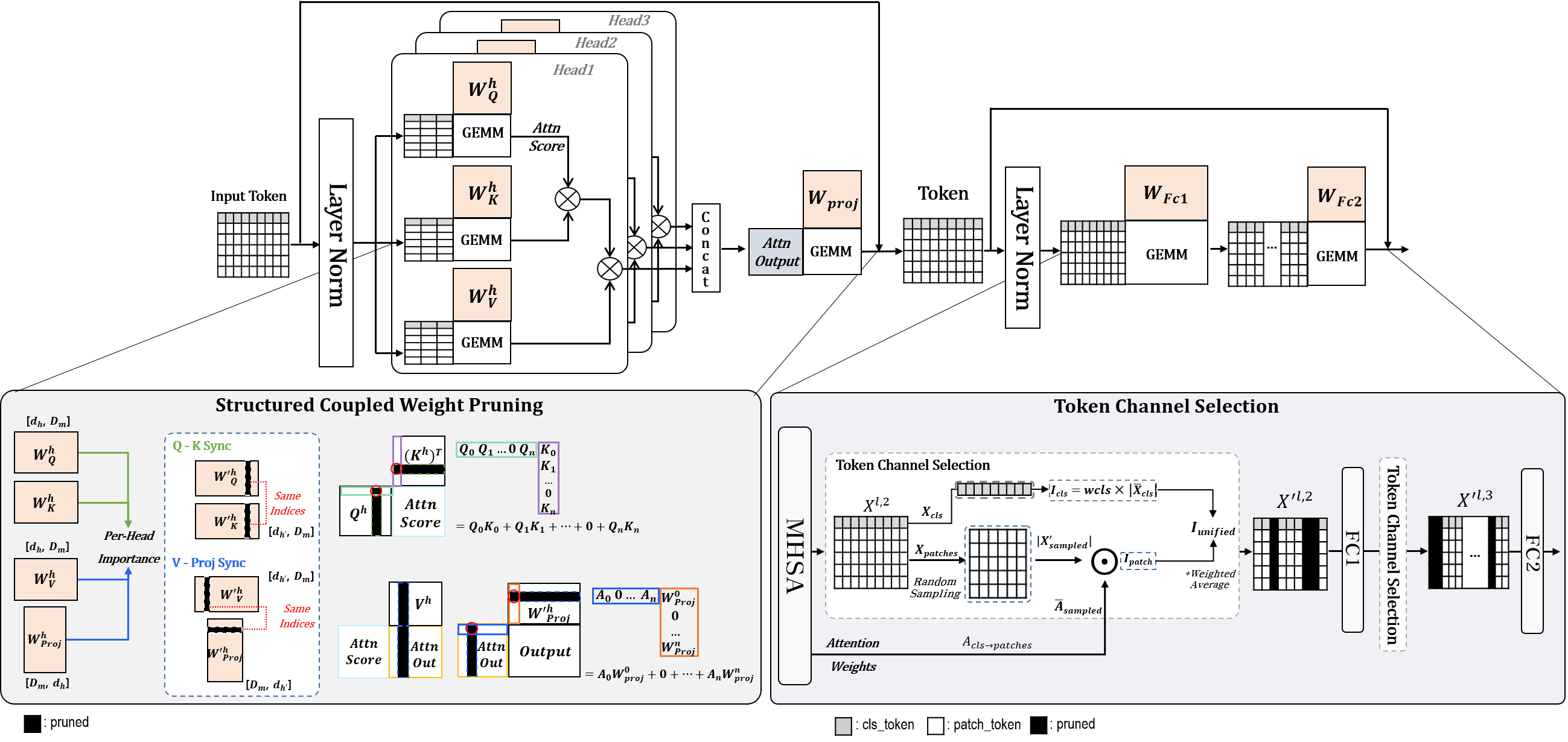
Figure 3. ToaSt 전체 구조: MHSA는 coupled pruning, FFN은 TCS로 분리 처리.
4. 실험 설정과 주요 결과
4.1 평가 설정
- 분류: ImageNet-1K
- 다운스트림: COCO 2017 detection (Cascade R-CNN/Mask R-CNN 백본)
- 백본: DeiT(T/S/B), ViT-MAE(B/L/H), Swin(T/S/B) 총 9개
- 측정: Top-1/Top-5, FLOPs, H100 기준 throughput/speedup
4.2 ImageNet 분류 결과
논문이 강조한 포인트는 "연산 감소 + 정확도 상승 동시 달성"입니다.
대표 결과는 다음과 같습니다.
- ViT-MAE-Huge: Top-1 88.52% (baseline 86.88 대비 +1.64%p), FLOPs 39.4% 감소, Throughput 1.59x
- DeiT-Small: Top-1 83.40% (baseline 79.82 대비 상승), FLOPs 45.7% 감소, Throughput 2.07x
- Swin-Base: Top-1 85.21% (baseline 83.50 대비 상승), FLOPs 42.7% 감소, Throughput 1.28x
토큰 압축 계열(ToMe, DiffRate)과 유사 FLOPs 구간 비교에서도 ToaSt가 더 높은 정확도를 보인 사례가 다수 제시됩니다.
4.3 Downstream 전이 성능 (COCO)
분류에서 만든 압축 백본을 detection에 전이했을 때도 성능이 유지됩니다.
- Swin-Small: 52.2 box mAP (baseline 51.9)
- Swin-Base(설정별): 52.2 / 51.8 box mAP
즉 단순히 분류 과적합용 pruning이 아니라, 백본 수준의 중복 제거로 이어질 가능성을 보여줍니다.
5. Ablation에서 확인된 핵심 포인트
논문은 구성 요소별 기여를 분리해 분석합니다.
- MHSA only: 속도는 개선되지만 정확도 하락이 발생하는 설정 존재
- MHSA + TCS(ToaSt): 속도 추가 개선 + 정확도 회복(또는 baseline 초과) 패턴 확인
또한 FFN의 FC1/FC2 민감도 분석에서,
- FC1은 초기 레이어에서 민감해 보수적 pruning이 유리
- FC2는 후반 레이어에서 높은 pruning 허용
이라는 비대칭 정책의 근거를 제시합니다.
논문은 이를 "TCS가 중복 채널 노이즈를 걸러 정확도 향상에도 기��여"하는 신호로 해석합니다.
6. 실무 관점에서의 해석
ToaSt를 실무 관점에서 보면 다음 장점이 있습니다.
- 모듈 분리 설계로 최적화가 비교적 단순
- FFN 중심 절감으로 실제 연산비 절감 기여가 큼
- structured 형태라 범용 GPU에서 가속 실현 가능성 높음
- 대형 모델일수록 복구 epoch가 줄어드는 경향 보고
특히 "모델이 커질수록 pruning 후 복구가 빠르다"는 관찰은 대형 파운데이션 모델 운영 환경에서 중요한 시사점입니다.
7. 한계와 향후 과제
저자들이 명시한 한계는 레이어별 pruning ratio를 수동 튜닝한다는 점입니다. 향후 방향은 아래와 같습니다.
- ratio 자동 탐색/학습화
- VLM으로의 확장
- quantization과의 결합
마무리
ToaSt는 ViT 압축에서 반복적으로 등장하는 두 문제를 동시에 겨냥합니다.
- token 중심 압축만으로는 FFN 중복 제거가 부족하다는 점
- 강하게 결합된 전역 최적화가 재학습 비용과 불안정성을 키운다는 점
이를 해결하기 위해 MHSA와 FFN을 분리해 각각 다른 원리로 압축했고, 논문 결과는 정확도-효율 trade-off에서 일관된 개선을 보여줍니다.
핵심 메시지는 명확합니다.
ViT 경량화는 "토큰만"이 아니라 "채널까지" 같이 봐야 한다. 그리고 모듈 특성에 맞춘 분리 설계가 실제 성능과 운영 효율을 함께 끌어올린다.

