EVA의 GPU MIG/MPS 최적 구성 가이드




EVA는 대규모 카메라 환경에서 Vision Model과 VLM을 안정적으로 운영하기 위해, 모델 추론뿐 아니라 GPU 분할과 프로세스 실행 방식까지 함께 최적화합니다. 이 과정에서 중요한 것은 단순히 더 높은 성능의 GPU를 사용하는 것이 아닙니다. Vision Model과 VLM이 동시에 동작하는 환경에서는 GPU 자원을 어떻게 나누고, 여러 추론 프로세스를 어떻게 실행할지에 따라 실제 서비스 성능이 크게 달라집니다.
EVA는 모델 최적화나 애플리케이션 레벨의 스케줄링에만 의존하지 않습니다. 서버에 장착된 GPU 개수, GPU별 메모리 용량, MIG 분할 가능 여부, MPS 적용 효과, Vision Worker와 vLLM 인스턴스의 배치 구조까지 함께 고려해 환경별 최적 구성으로 배포합니다.
즉, EVA는 AI 모델을 실행하는 서비스에 그치지 않고, HW 단계의 GPU 구성과 Serving Framework의 동작 방식까지 고려하��여 시스템 자원을 최대한 효율적으로 활용합니다. 이를 통해 제한된 서버 자원에서도 다수의 카메라 요청을 안정적으로 처리할 수 있도록 구성합니다.
이번 글에서는 실제 EVA 실험 데이터를 기반으로 다음 세 가지 관점에서 MIG/MPS 적용 효과를 비교합니다.
- 다중 GPU 서버(PRO 5000 x3)에서 MIG 적용 효과
- 단일 GPU 서버(PRO 6000 x1)에서 MIG 적용 효과
- Vision Worker가 많은 환경에서 MPS 적용 효과
이를 통해 MIG와 MPS를 무조건 적용하는 것이 아니라, 서버 구성과 워크로드 특성에 따라 어떤 조합이 EVA 운영에 가장 적합한지 판단할 수 있는 기준을 제시합니다.
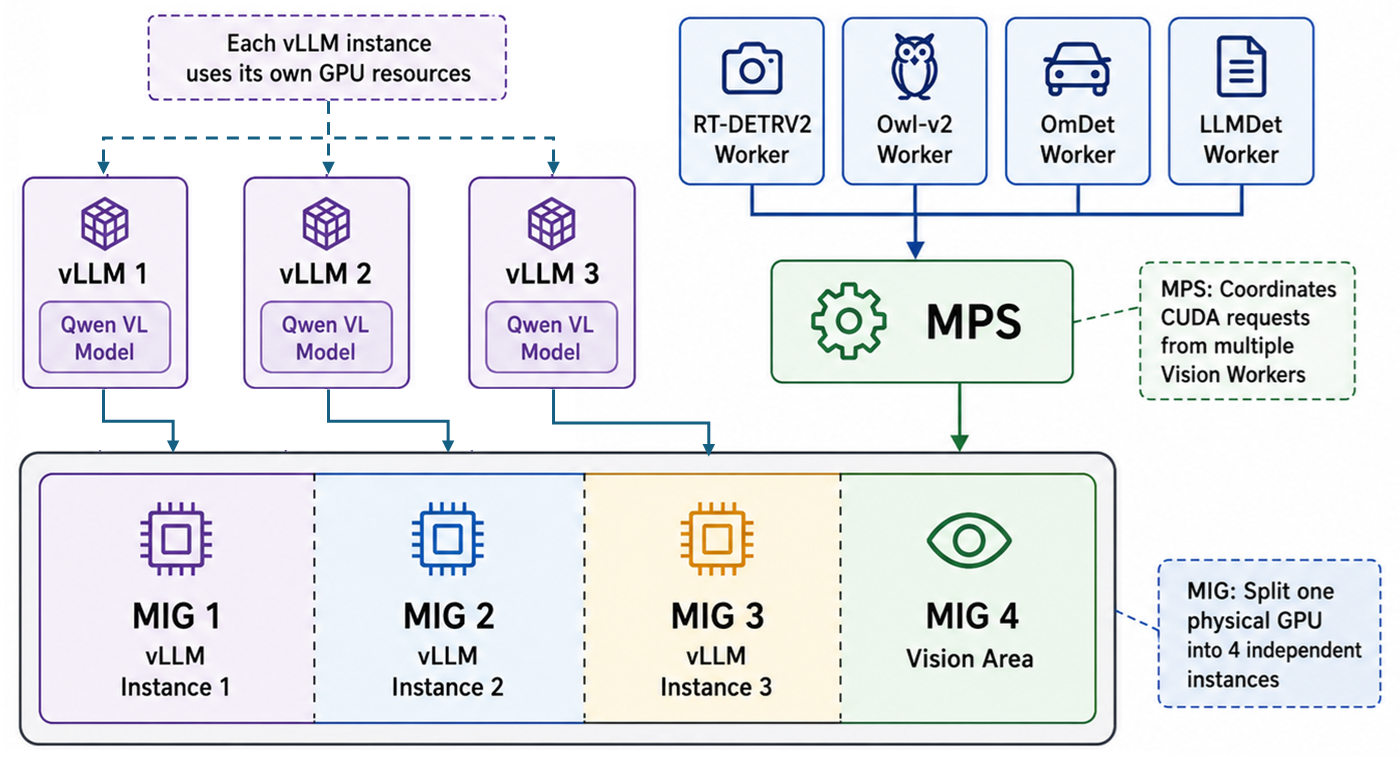
- MIG(Multi-Instance GPU): 하나의 물리 GPU를 여러 개의 독립 GPU 인스턴스로 분할하는 기능입니다. Vision과 vLLM을 서로 다른 인스턴스에 배치해 자원 경합을 줄일 수 있습니다.
- MPS(Multi-Process Service): 여러 CUDA 프로세스 요청을 하나의 서버 프로세스가 받아 GPU 실행을 조정하는 기능입니다. 다중 프로세스 환경에서 컨텍스트 전환 오버헤드를 완화할 수 있습니다.
1. EVA 추론 구조
EVA 서버에서는 크게 두 계층의 추론 파이프라인이 동시에 동작합니다.
- Vision: RT-DETRV2, Owl-v2, OmDet, LLMDet 등 다양한 객체 탐지 모델을 여러 Worker 프로세스로 병렬 처리
- vLLM(VLM Serving): Agent 요청을 받아 사용자가 작성한 시나리오를 여러 Task로 분해하고, 단계별 추론을 통해 해당 상황인지 판단
EVA의 추론 구조에서 중요한 점은 Vision과 vLLM의 GPU 사용 패턴이 서로 다르다는 것입니다.
| 구분 | GPU 사용 특성 |
|---|---|
| Vision | 다수 Worker가 짧은 추론 요청을 자주 발생시킴 |
| vLLM | 연속 배칭을 통해 비교적 큰 단위의 추론을 처리함 |
| 혼합 구동 | Vision과 vLLM이 같은 GPU를 공유하면 컨텍스트 스위칭 비용이 누적될 수 있음 |
카메라가 많이 사용하는 모델일수록 해당 모델에 더 많은 Worker를 배정해 모델별 추론 요청을 병렬로 처리합니다. 반면 vLLM은 continuous batching을 통해 여러 요청을 한 번에 처리하므로, 단순히 인스턴스 수를 늘린다고 항상 처리량이 증가하지는 않습니다.
따라서 EVA에서는 서버 구성과 워크로드 특성에 따라 MIG와 MPS 적용 여부를 다르게 판단해야 합니다.
2. 실험 환경
2.1 서버 구성
이번 실험은 다음 두 가지 GPU 서버 구성을 기준으로 진행했습니다.
| 서버 | GPU 구성 | MIG 활성화 시 구성 |
|---|---|---|
| 서버 A | RTX PRO 5000 48GB x 3 | 24GB x 6 |
| 서버 B | RTX PRO 6000 96GB x 1 | 24GB x 4 |
2.2 서비스 배치
EVA는 Vision과 vLLM의 GPU 사용 패턴이 다르기 때문에, 두 워크로드를 어떤 GPU 또는 MIG 인스턴스에 배치하는지가 중요합니다.
기본적으로 Vision은 객체 탐지 요청을 처리하는 영역으로 구성하고, vLLM은 Agent의 VLM 기반 판단 요청을 처리하는 영역으로 구성합니다. MIG를 적용하는 경우에는 Vision이 사용하는 GPU 또는 MIG 슬라이스를 제외한 나머지 GPU 자원에 vLLM 인스턴스를 각각 하나씩 구성합니다.
예를 들어 PRO 5000 x3 서버에서 MIG를 적용하면 총 6개의 24GB MIG 슬라이스가 생성됩니다. 이 중 1개 슬라이스는 Vision에 할당하고, 나머지 5개 슬라이스에는 vLLM 인스턴스를 각각 1개씩 배치합니다. PRO 6000 x1 서버에서도 동일하게 4개의 24GB MIG 슬라이스 중 1개는 Vision, 나머지 3개는 vLLM 인스턴스로 구성합니다.
| 환경 | MIG | 배치 구성 | 설명 |
|---|---|---|---|
| PRO 5000 x3 | X | Vision / vLLM / vLLM | 물리 GPU 3개 중 1개는 Vision, 나머지 2개는 vLLM 인스턴스로 사용 |
| PRO 5000 x3 | O | Vision / vLLM / vLLM / vLLM / vLLM / vLLM | 24GB MIG 슬라이스 6개 중 1개는 Vision, 나머지 5개는 vLLM 인스턴스로 사용 |
| PRO 6000 x1 | X | Vision + vLLM | 단일 96GB GPU에서 Vision과 vLLM이 함께 동작 |
| PRO 6000 x1 | O | Vision / vLLM / vLLM / vLLM | 24GB MIG 슬라이스 4개 중 1개는 Vision, 나머지 3개는 vLLM 인스턴스로 사용 |
이 구성은 Vision과 vLLM을 최대한 분리하여 자원 경합을 줄이고, vLLM 인스턴스를 남은 GPU 자원에 고르게 배치했을 때 MIG가 실제 처리량 개선으로 이어지는지를 확인하기 위한 실험입니다.
3. 지표 정의
이번 글에서는 Vision과 Agent 처리량을 다음 기준으로 비교했습니다.
| 지표 | 정의 |
|---|---|
| Vision 처리량 | req/s |
| Agent 처리량 | req/min |
환산식은 다음과 같습니다.
- Vision
req/s= 1시간 누적 Vision 처리 건수 / 3600 - Agent
req/min= 1시간 누적 VLM responses / 60
4. PRO 5000 x3 환경에서 MIG 적용 효과
4.1 실측 결과
| MIG | MPS | VLM responses | VLM Latency | Vision Throughput (req/s) | Agent Throughput (req/min) |
|---|---|---|---|---|---|
| X | X | 2,287 | 10.39 s | 29.36 | 38.11 |
| O | O | 2,229 | 10.84 s | 22.63 | 37.15 |
4.2 해석
다중 GPU 환경인 PRO 5000 x3 구성에서는 MIG로 vLLM 인스턴스를 늘려도 vLLM 처리량 개선 효과가 크지 않았습니다.
이미 vLLM이 continuous batching을 통해 동시 요청을 효율적으로 처리하고 있었기 때문에, 인스턴스 수 증가가 곧바로 처리량 향상으로 이어지지 않았습니다. 또한 MIG 분할로 인한 인스턴스별 가용 자원 축소와 전체 워크로드 배치 변화가 함께 작용하면서 Vision 처리량은 감소하는 경향을 보였습니다.
운영 관점에서는 MIG 적용 시 다음 요소를 함께 고려해야 합니다.
- MIG 분할 정책 관리
- 인스턴스별 모니터링
- 장애 발생 시 재배치 및 복구 절차
- 워크로드별 인스턴스 크기 조정
따라서 PRO 5000 x3와 같은 다중 GPU 환경에서는 기본적으로 MIG 미적용 구성을 우선 검토하고, Vision과 vLLM 간 자원 충돌이 명확하게 확인되는 경우에만 MIG 적용을 고려하는 것이 적절합니다.
5. PRO 6000 x1 환경에서 MIG 적용 효과
5.1 실측 결과
| MIG | MPS | VLM responses | VLM Latency | Vision Throughput (req/s) | Agent Throughput (req/min) |
|---|---|---|---|---|---|
| X | X | 712 | 47.20 s | 20.33 | 11.87 |
| O | O | 1,032 | 32.10 s | 26.33 | 17.20 |
5.2 해석
단일 GPU 환경인 PRO 6000 x1 구성에서는 MIG 적용 효과가 명확하게 나타났습니다.
MIG 미적용 상태에서는 Vision Worker와 vLLM이 하나의 물리 GPU를 공유합니다. 이 경우 Vision의 다수 Worker가 짧은 추론 요청을 반복적으로 발생시키고, vLLM은 비교적 큰 단위의 추론을 처리하기 때문에 GPU 점유권 전환이 자주 발생할 수 있습니다.
MIG를 적용해 Vision과 vLLM이 사용하는 GPU 자원을 하드웨어 레벨의 독립 인스턴스로 격리하면, 워크로드 간 자원 경합을 줄이고 각 추론 파이프라인을 더 안정적으로 실행할 수 있습니다.
| 항목 | MIG 미적용 | MIG 적용 | 변화 |
|---|---|---|---|
| VLM responses | 712 | 1,032 | +44.9% |
| VLM Latency | 47.20 s | 32.10 s | -32.0% |
| Agent Throughput | 11.87 req/min | 17.20 req/min | +44.9% |
| Vision Throughput | 20.33 req/s | 26.33 req/s | +29.5% |
이 결과를 보면 단일 GPU에서 Vision과 vLLM을 함께 운영해야 하는 고밀도 환경에서는 MIG가 효과적인 선택이 될 수 있습니다. 특히 Vision과 vLLM의 GPU 사용 패턴이 크게 다를수록, MIG를 통한 하드웨어 레벨 격리 효과가 더 크게 나타납니다.
6. Vision Worker가 많은 환경에서 MPS 적용 효과
Vision 모델은 여러 Worker 프로세스가 동시에 GPU에 요청을 보내는 구조로 동작합니다. 이때 Worker 수가 많아지면 프로세스 간 GPU 점유 전환이 빈번해질 수 있습니다.
MPS를 적용하면 여러 CUDA 프로세스 요청을 하나의 MPS 서버가 조정하여 처리하므로, 다중 프로세스 환경에서 컨텍스트 전환 오버헤드를 줄이고 GPU 활용률을 높일 수 있습니다.
이번 실험에서는 PRO 5000 환경에서 MIG를 적용하지 않은 상태로 MPS 효과를 비교했습니다.
| MIG | MPS | Total requests | Total throughput | RT-DETRV2 | Owl-v2 | OmDet | LLMDet |
|---|---|---|---|---|---|---|---|
| X | X | 7,131 | 23.770 req/s | 4.337 req/s | 5.597 req/s | 10.953 req/s | 2.883 req/s |
| X | O | 7,794 | 25.980 req/s | 4.490 req/s | 7.447 req/s | 11.120 req/s | 2.923 req/s |
MPS 적용 결과, Vision 전체 처리량은 23.770 req/s에서 25.980 req/s로 약 9.3% 증가했습니다.
모델별로 보면 Owl-v2의 처리량 증가폭이 가장 컸고, RT-DETRV2, OmDet, LLMDet도 소폭 개선되었습니다. 이는 Vision Worker가 많은 환경에서 MPS가 다중 프로세스 요청을 보다 안정적으로 조정하는 데 도움이 될 수 있음을 보여줍니다.
7. 최종 결론
이번 실험을 통해 MIG와 MPS는 모든 환경에 동일하게 적용하는 기능이 아니라, GPU 구성과 워크로드 특성에 따라 선택적으로 적용해야 한다는 점을 확인했습니다.
7.1 다중 GPU 서버(PRO 5000 x3)
PRO 5000 x3처럼 물리 GPU가 여러 개인 환경에서는 Vision과 vLLM을 GPU 단위로 분리할 수 있습니다. 이 경우 MIG를 추가로 적용해 vLLM 인스턴스를 늘리더라도 처리량 개선 효과는 제한적이었습니다.
- vLLM은 이미 continuous batching으로 동시 요청을 효율적으로 처리
- 인스턴스 수 증가가 처리량 향상으로 바로 이어지지 않음
- MIG 분할 시 운영 복잡도와 자원 단편화 가능성 증가
- 기본 구성은 MIG 미적용을 우선 권장
7.2 단일 GPU 서버(PRO 6000 x1)
PRO 6000 x1처럼 하나의 물리 GPU에서 Vision과 vLLM을 함께 운영해야 하는 환경에서는 MIG 적용 효과가 컸습니다.
- Vision과 vLLM의 GPU 사용 패턴이 다름
- 단일 GPU 공유 시 컨텍스트 스위칭 비용이 커질 수 있음
- MIG 적용 시 워크로드 간 자원 경합 완화
- 단일 GPU 고밀도 구성에서는 MIG 우선 검토 권장
7.3 Vision Worker가 많은 환경
Vision Worker가 많은 환경에서는 MPS 적용이 효과적일 수 있습니다.
- 다수 Worker가 동시에 GPU 요청을 발생
- 프로세스별 GPU 점유 전환 비용 증가 가능
- MPS 적용 시 Vision 전체 처리량 약 9.3% 증가
- Vision 중심 서버에서는 MPS 적용을 기본 옵션으로 검토
8. 운영 권장안
| 운영 환경 | 권장 구성 |
|---|---|
| 다중 GPU + vLLM 중심 서버 | MIG 미적용으로 시작하고, 병목이 명확할 때만 MIG 도입 |
| 단일 GPU + Vision/VLM 혼합 서버 | MIG 우선 검토 |
| Vision Worker가 많은 서버 | MPS 적용 검토 |
| Vision과 vLLM을 GPU 단위로 분리 가능한 서버 | 물리 GPU 분리를 우선 활용 |
| GPU 메모리가 부족한 서버 | MIG보다 모델 배치와 Worker 수 조정을 우선 검토 |
정리하면, EVA에서는 MIG와 MPS를 단순히 “켜는 기능”으로 보지 않습니다. 서버 구성, Vision/VLM 배치, Worker 수, vLLM 처리 방식, 운영 복잡도를 함께 고려해 환경별 최적 구성을 선택합니다.
9. 참고 자료
이번 분석 글의 프레임을 정리할 때 아래 자료의 관점을 참고했습니다.
- NVIDIA 기술 블로그: Getting the Most Out of the NVIDIA A100 GPU with Multi-Instance GPU https://developer.nvidia.com/blog/getting-the-most-out-of-the-a100-gpu-with-multi-instance-gpu/
- NVIDIA 기술 블로그: Boost GPU Memory Performance with No Code Changes Using NVIDIA CUDA MPS https://developer.nvidia.com/blog/boost-gpu-memory-performance-with-no-code-changes-using-nvidia-cuda-mps/
- NVIDIA 공식 문서: Multi-Process Service (MPS) https://docs.nvidia.com/deploy/mps/latest/index.html
- vLLM 공식 블로그 https://vllm.ai/blog
- Anyscale 기술 블로그: Continuous Batching 기반 vLLM 처리량 분석 https://www.anyscale.com/blog/continuous-batching-llm-inference

