ToaSt: Decoupled Compression for Faster and More Accurate ViTs (ICML 2026)

The ToaSt paper has been accepted to ICML 2026, one of the top conferences in AI.
Vision Transformers (ViTs) power a wide range of tasks, from classification and detection to segmentation and multimodal backbones. But their high compute cost often becomes a deployment bottleneck.
In this post, we walk through the ICML 2026 ToaSt paper in detail: the motivation, method design, and key experimental results.
The core idea of ToaSt can be summarized in one line:
- Decouple MHSA and FFN compression, optimize them with different strategies, and improve the accuracy-efficiency trade-off while avoiding cross-layer propagation issues.
1. Background: Where ViTs become expensive
ViT compute mainly comes from two sources:
- Attention: roughly (O(N^2)) with token length (N)
- FFN: heavy channel-wise computation around hidden dimension (D)
As highlighted in the paper, a standard ViT spends about 61% of FLOPs in FFN and around 19% in attention. This means attention-only acceleration is not enough; FFN redundancy must be addressed directly.
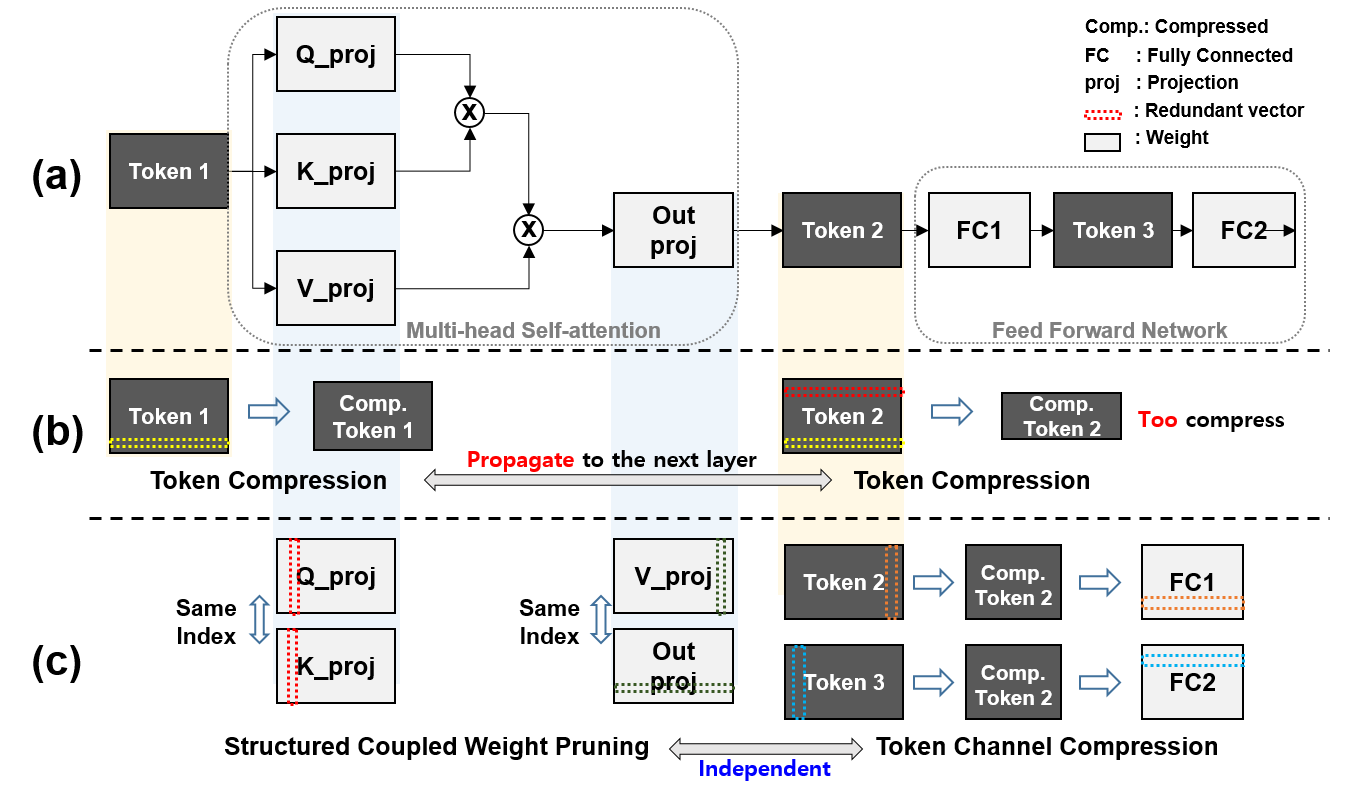
Figure 1. ToaSt decouples MHSA and FFN compression to avoid harmful cross-layer propagation.
2. Limits of prior approaches
The paper groups prior ViT acceleration methods into three categories.
2.1 Structured Weight Pruning
- Strength: removes heads/channels/blocks in hardware-friendly structured form
- Limitation: often requires long retraining to recover accuracy
- Practical issue: ViTs are already expensive to train, so long post-pruning fine-tuning is costly
2.2 Token Compression / Token Merging
- Strength: directly reduces attention cost by shrinking (N)
- Limitation 1: does not directly target dominant FFN (D^2) complexity
- Limitation 2: token decisions propagate globally to later layers, making optimization harder
2.3 Joint / Hybrid Methods
- Strength: can optimize multiple axes at once
- Limitation: more coupled optimization and higher tuning complexity
- Some approaches are also more hardware/kernel dependent in practice
ToaSt takes a different route: not one large coupled optimization, but module-wise decoupled compression.
3. Method: ToaSt as Layer-Independent Compression
ToaSt preserves each block interface ((N \times D)) while compressing internal computation. This reduces the cascading side effects caused by global structural changes.
3.1 MHSA: Coupled Structured Pruning
In MHSA, Q/K/V/Proj are mathematically coupled. ToaSt enforces synchronized index pruning rather than pruning them independently.
- Q-K synchronized pruning
- V-Proj synchronized pruning
- Reduce per-head internal dimension (d_k), while preserving the global interface dimension (D)
Importance is computed with a geometric-median-based criterion. Except for small-model settings, the first layer is typically preserved and later layers are pruned aggressively. The paper reports that aligned (coupled) pruning significantly mitigates accuracy collapse compared with non-aligned pruning at high pruning ratios.
3.2 FFN: Token Channel Selection (TCS)
FFN has a (D \rightarrow 4D \rightarrow D) structure and dominates total FLOPs. ToaSt introduces training-free dynamic channel selection (TCS) for FFN.
The paper’s FFN analysis reports three consistent patterns:
- increasing activation sparsity in deeper layers
- collapsing effective rank
- high (R^2) reconstruction, indicating strong linear channel redundancy
Based on this, TCS samples a subset of tokens, estimates channel importance, and keeps only informative channels. Its importance metric combines global CLS-driven context and patch saliency; for CLS-free architectures (e.g., Swin), patch-only scoring is used.
The pruning policy is asymmetric:
- FC1 (expansion) is pruned conservatively
- FC2 (reduction) is pruned more aggressively in deeper layers (up to 90% in the reported setup)
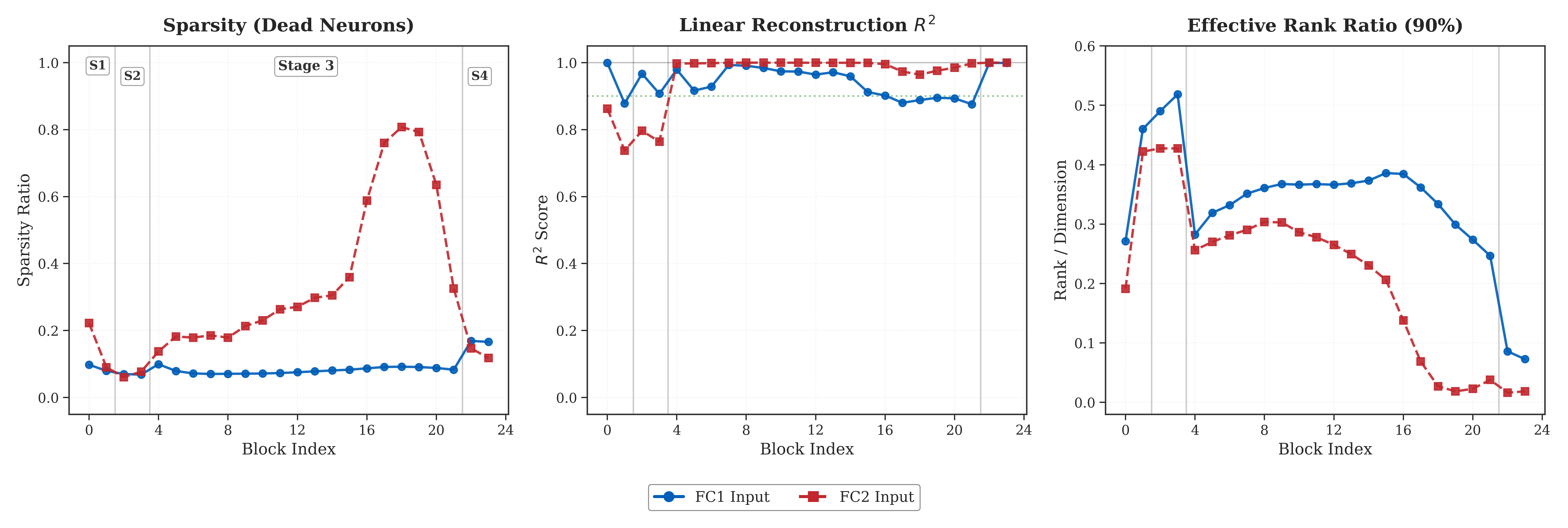
Figure 2. Swin-Base FFN analysis: redundancy increases in deeper layers.
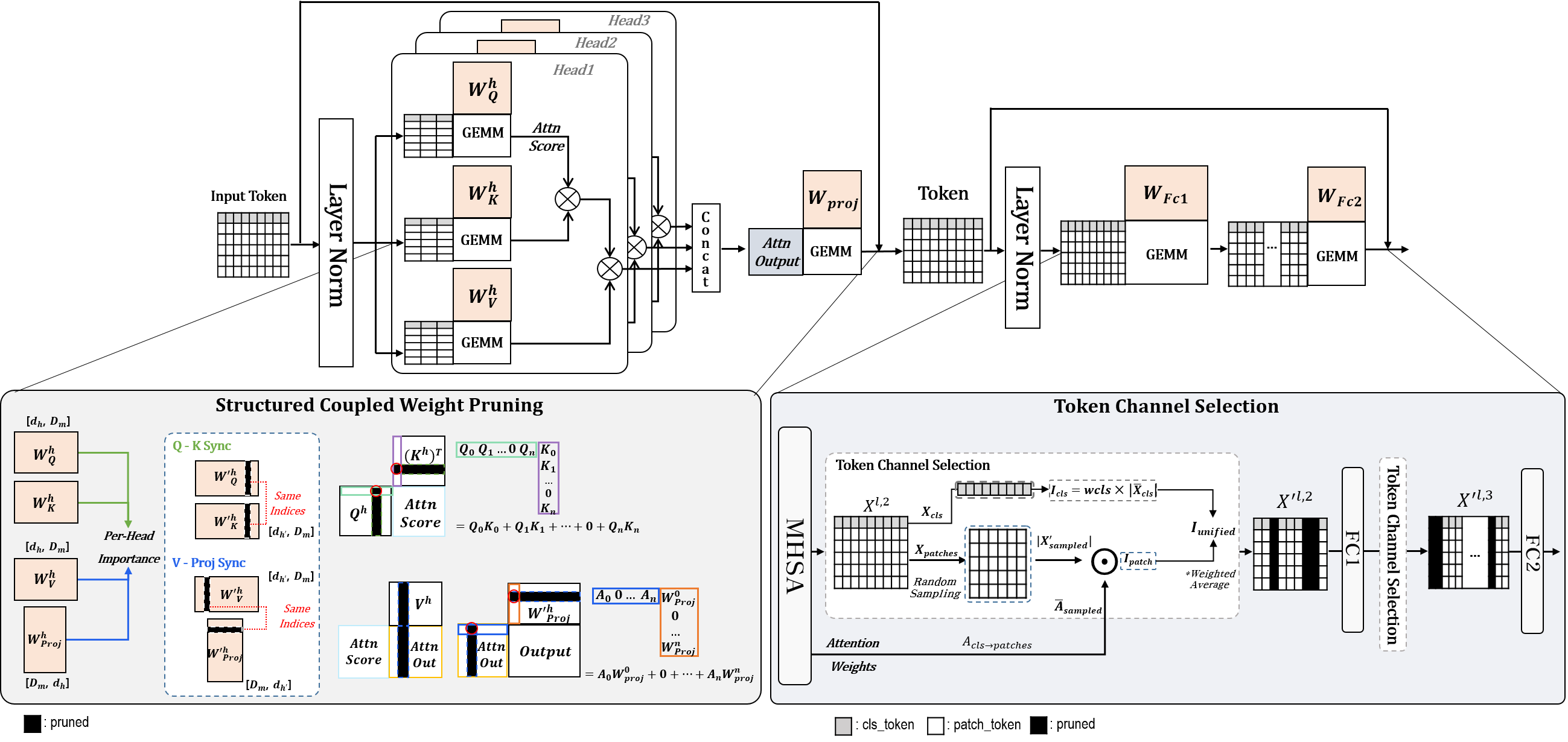
Figure 3. ToaSt overview: coupled MHSA pruning + FFN TCS.
4. Experimental setup and key results
4.1 Setup
- Classification: ImageNet-1K
- Downstream transfer: COCO 2017 detection (Cascade R-CNN / Mask R-CNN pipelines)
- Backbones: 9 models across DeiT (T/S/B), ViT-MAE (B/L/H), Swin (T/S/B)
- Metrics: Top-1/Top-5, FLOPs, and throughput/speedup on H100
4.2 ImageNet results
The main message is simultaneous compute reduction and accuracy gain.
- ViT-MAE-Huge: Top-1 88.52% (vs. 86.88 baseline, +1.64%p), 39.4% FLOPs reduction, 1.59x throughput
- DeiT-Small: Top-1 83.40% (vs. 79.82 baseline), 45.7% FLOPs reduction, 2.07x throughput
- Swin-Base: Top-1 85.21% (vs. 83.50 baseline), 42.7% FLOPs reduction, 1.28x throughput
At similar FLOPs budgets, the paper reports multiple cases where ToaSt outperforms token-compression baselines such as ToMe and DiffRate.
4.3 Downstream transfer (COCO)
Compressed backbones remain competitive when transferred to detection:
- Swin-Small: 52.2 box mAP (baseline 51.9)
- Swin-Base variants: 52.2 / 51.8 box mAP
This suggests ToaSt removes architectural redundancy rather than only overfitting classification behavior.
5. What the ablations show
The ablations separate the contribution of each component:
- MHSA-only: often improves speed but can hurt accuracy
- MHSA + TCS (full ToaSt): adds more speed and recovers (or exceeds) baseline accuracy
The FC1/FC2 sensitivity analysis also supports the asymmetric pruning policy:
- FC1 is more sensitive in early layers
- FC2 tolerates aggressive pruning in later layers
The paper interprets this as a sign that TCS filters redundant channel noise and can behave like implicit regularization.
6. Practical takeaways
From an engineering perspective, ToaSt is attractive because:
- decoupled modules simplify optimization
- FFN-focused reduction targets the dominant compute cost
- structured outputs are hardware-friendly on commodity GPUs
- larger models appear to need fewer recovery epochs after pruning
The reported inverse scaling trend in recovery epochs is especially interesting for large foundation backbones.
7. Limitations and future work
The paper explicitly notes one current limitation: layer-wise pruning ratios are manually tuned. Future directions include:
- learnable/automatic ratio optimization
- extension to VLM settings
- combination with quantization
Conclusion
ToaSt addresses two recurring ViT compression pain points at once:
- token-only compression is insufficient for FFN-dominant compute
- globally coupled pruning often increases retraining cost and instability
By decoupling MHSA and FFN compression and tailoring each to its own structure, ToaSt achieves a strong and consistent accuracy-efficiency trade-off across model families.
The key message is simple:
For ViT acceleration, token reduction alone is not enough. Channel redundancy in FFN must be addressed, and decoupled module-aware design is a practical way to do it.

