Mellerikat for Splunk User Manual
진행 순서
- 초기 설정
- AI Solution 등록
- Train 데이터 선택
- 데이터셋 생성 및 모델 학습과 배포
- Inference 수행
1. 초기 설정
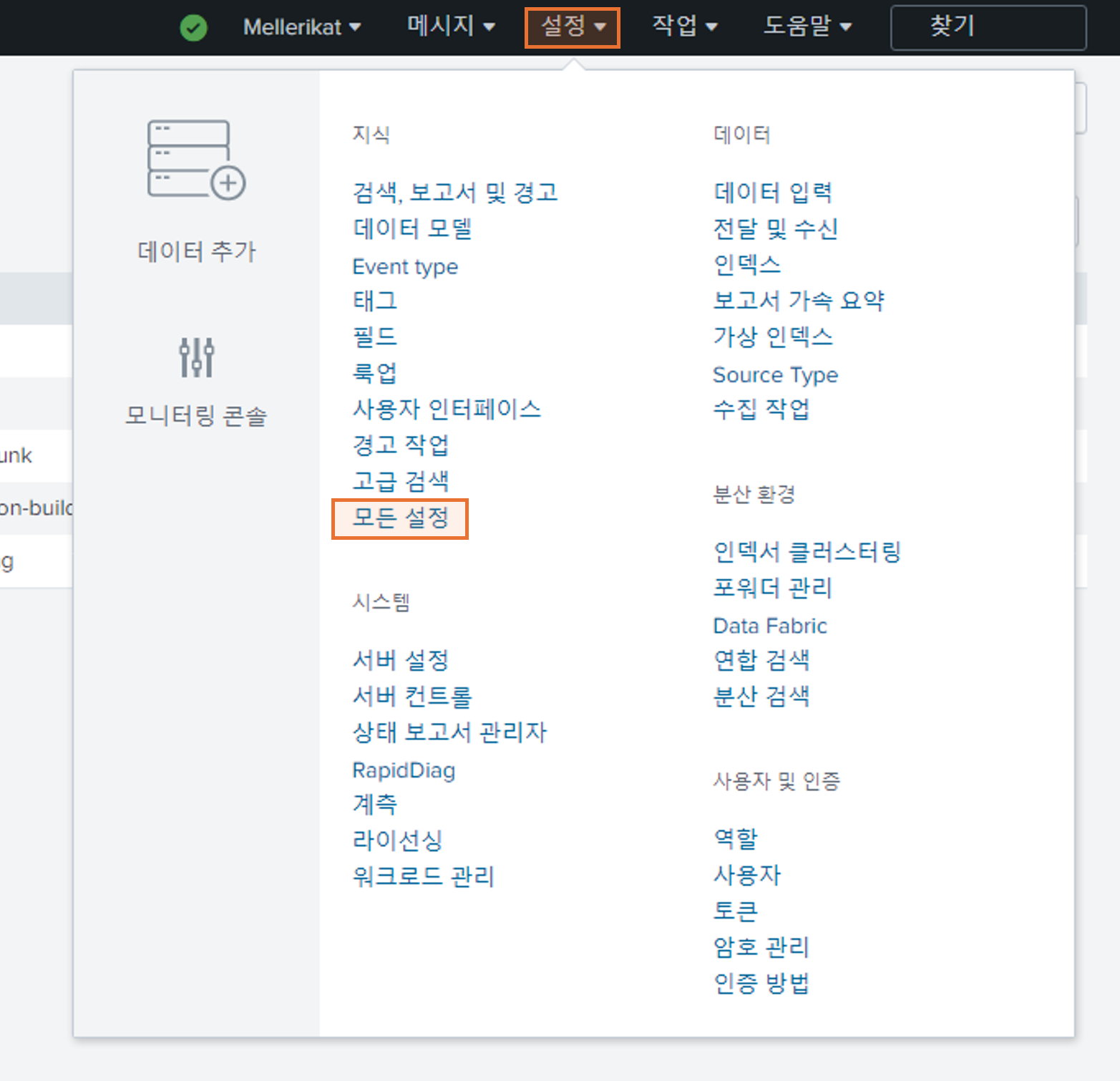
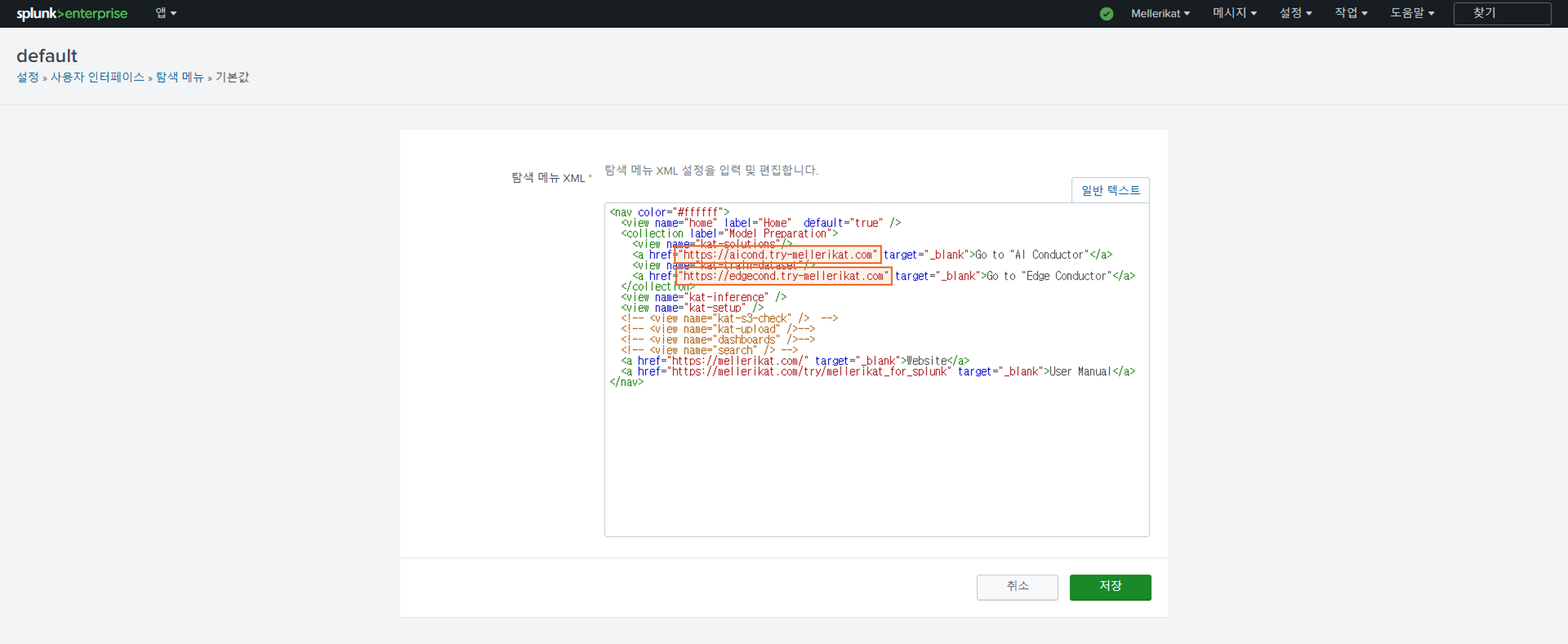
- Splunk Enterprise의 '모든 설정' 항목에 들어가 구축된 AI Conductor와 Edge Conductor 주소를 설정합니다.

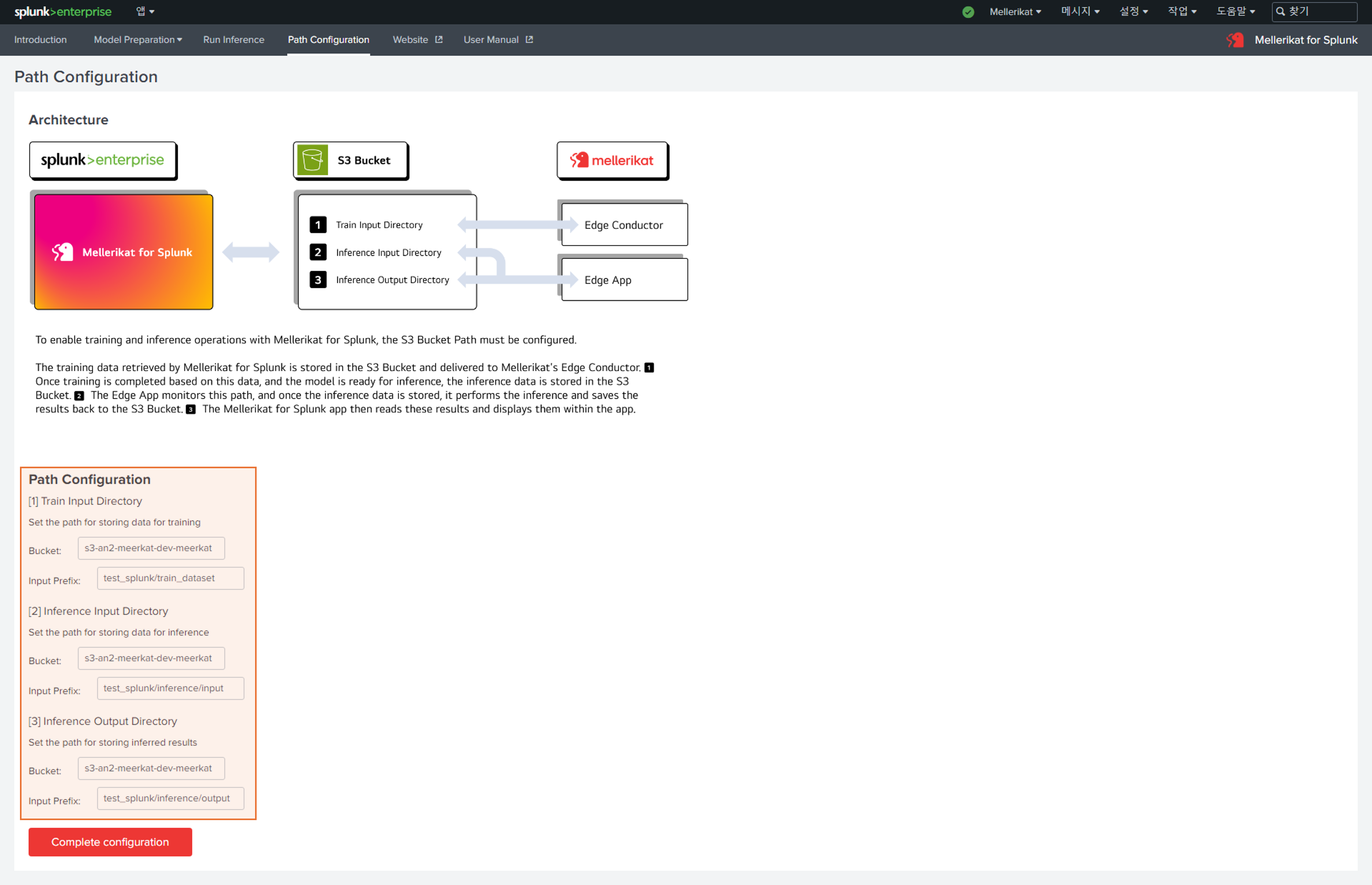
- Path Configuration 탭을 선택 후, 데이터를 저장하고 불러올 경로를 설정합니다.
2. AI Solution 등록
- Create AI Solution 탭으로 이동하여 가이드에 따라 splunk.yaml 파일을 저장합니다.
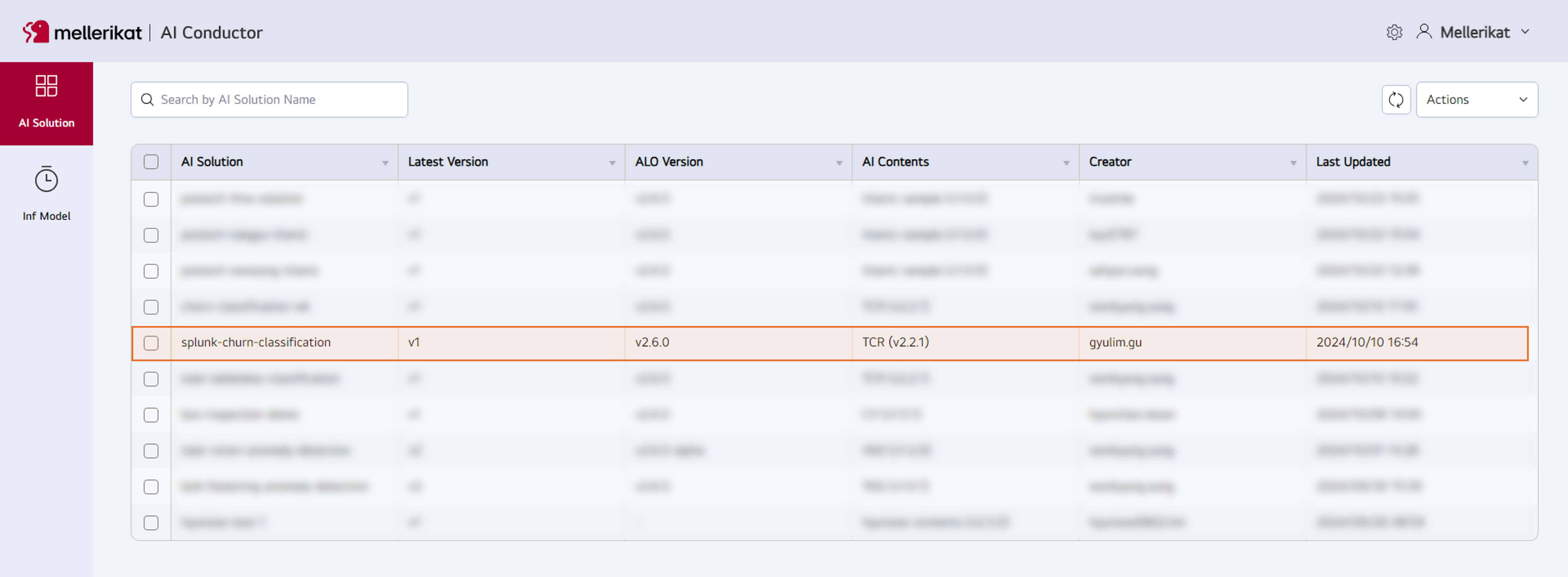
- AI Conductor에서 등록된 AI Solution을 확인합니다.
3. Train 데이터 선택
- 모델 학습을 진행할 데이터를 확인합니다.
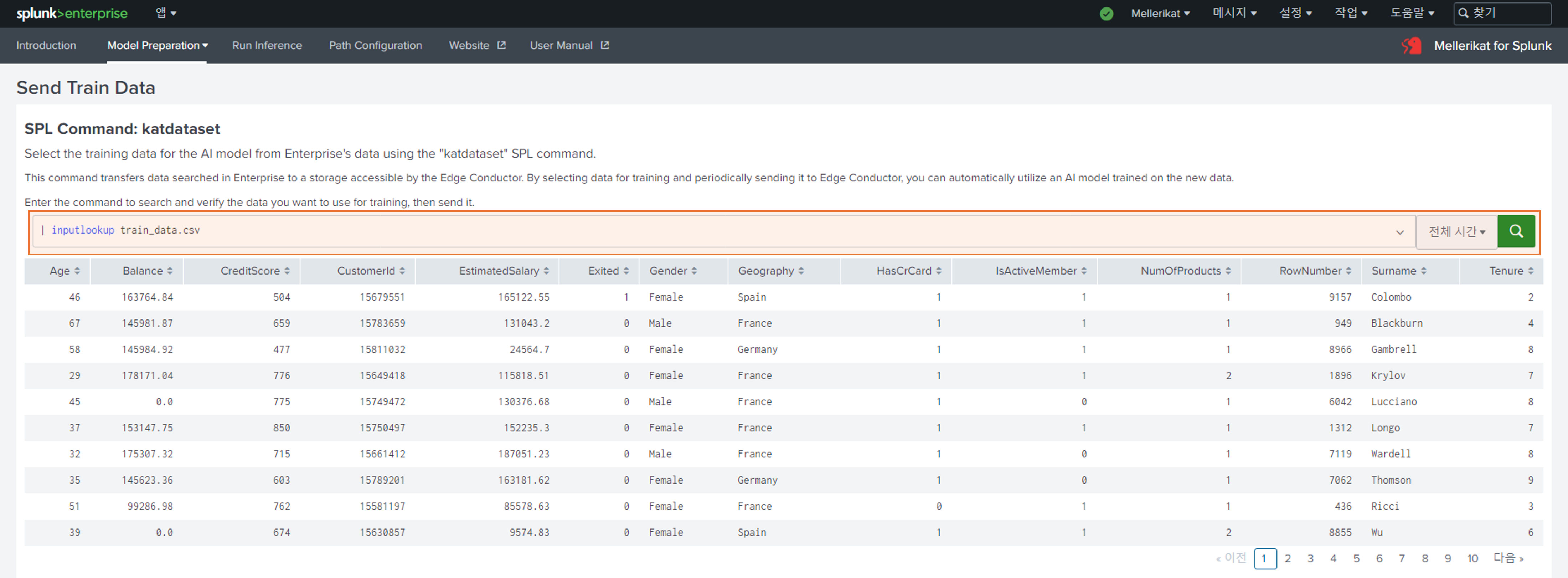
- 저장할 파일명을 입력하고, Send 버튼을 눌러 지정된 경로로 데이터를 전송합니다.

4. 데이터셋 생성 및 모델 학습과 배포
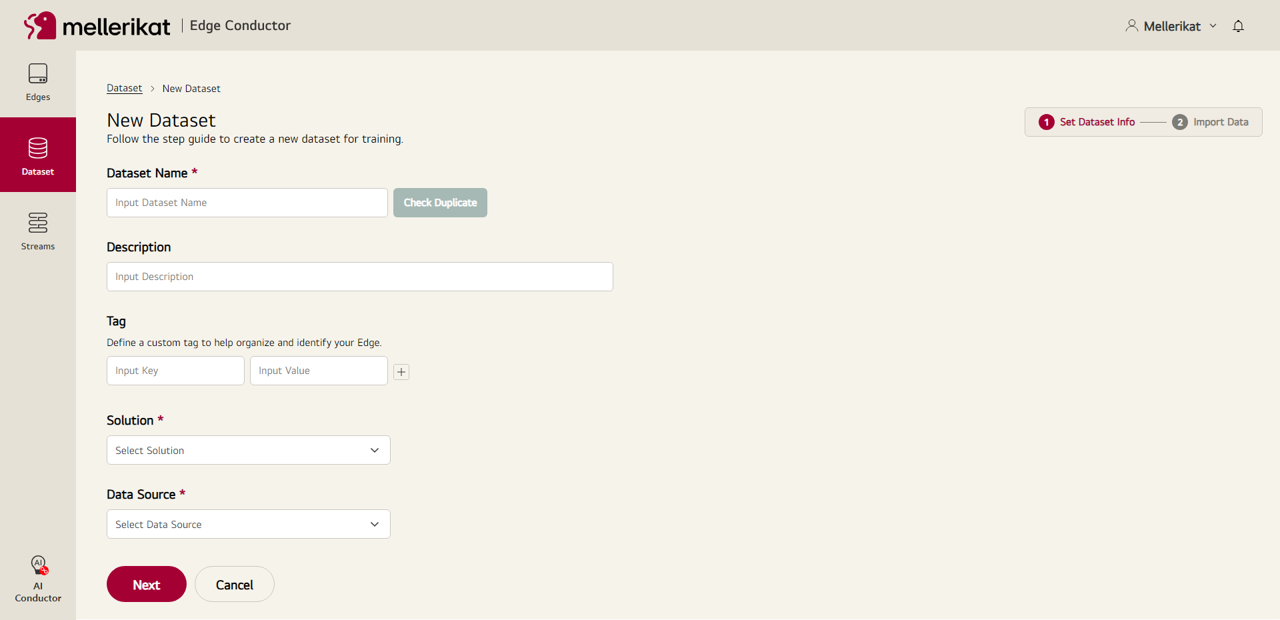
- Edge Conductor에 접속 후, Dataset 탭으로 들어와 New Dataset 버튼을 클릭합니다.
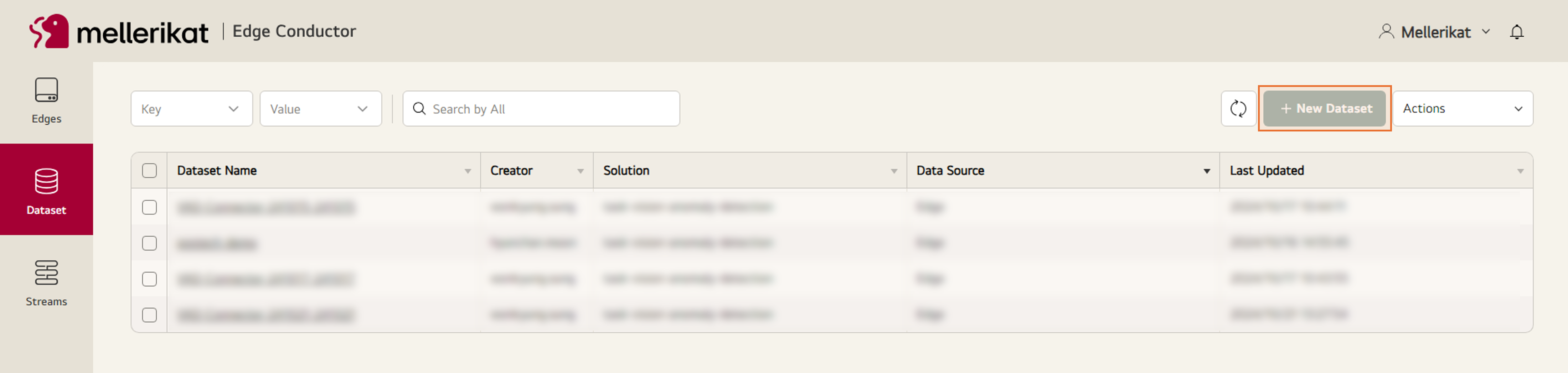
- Dataset에 필요한 정보를 입력 후 Next 버튼을 클릭합니다.
- Dataset Name: 생성할 Dataset의 이름 * required
- Description: 생성할 Dataset의 설명
- Tag: Dataset에 부여할 태그 정보
- Solution: 해당 Dataset과 연동할 AI Solution 이름 * required
- Data Source: Dataset을 가져올 경로의 종류 * required
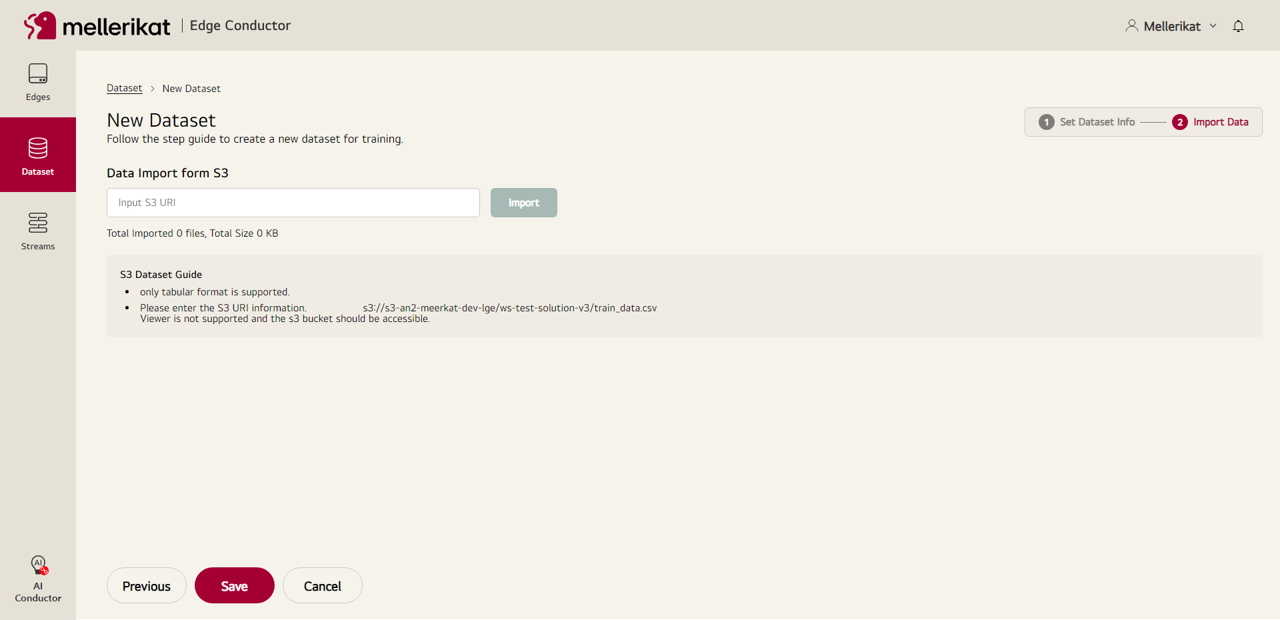
- Configuration 탭에서 설정한 S3 경로를 입력 후 Import 버튼을 클릭하여 데이터를 가져온 뒤 Save 버튼을 눌러 Dataset을 저장합니다.
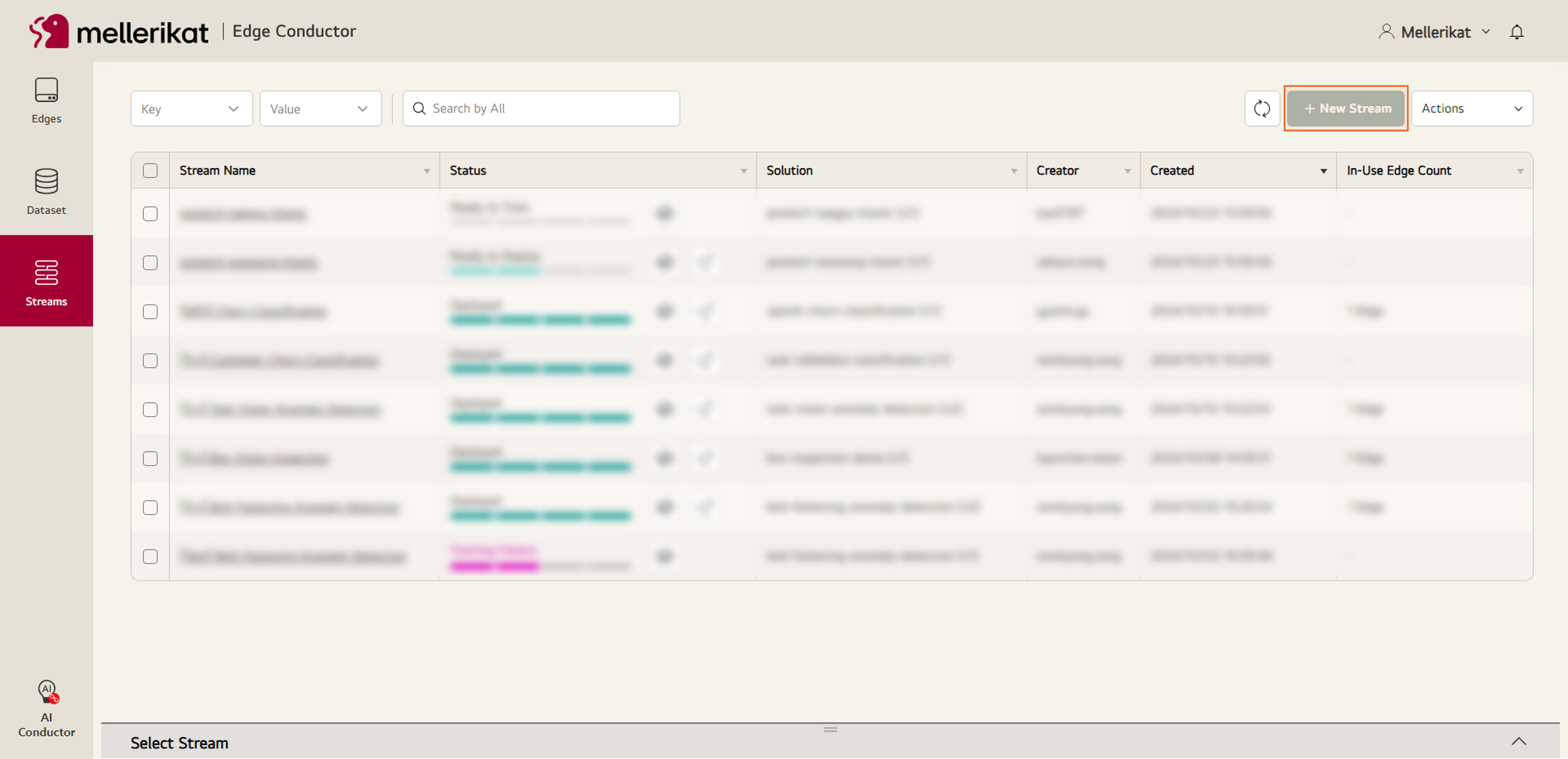
- Streams 탭으로 이동 후 New Stream 버튼을 클릭합니다.
- 생성한 AI Solution을 선택합니다.
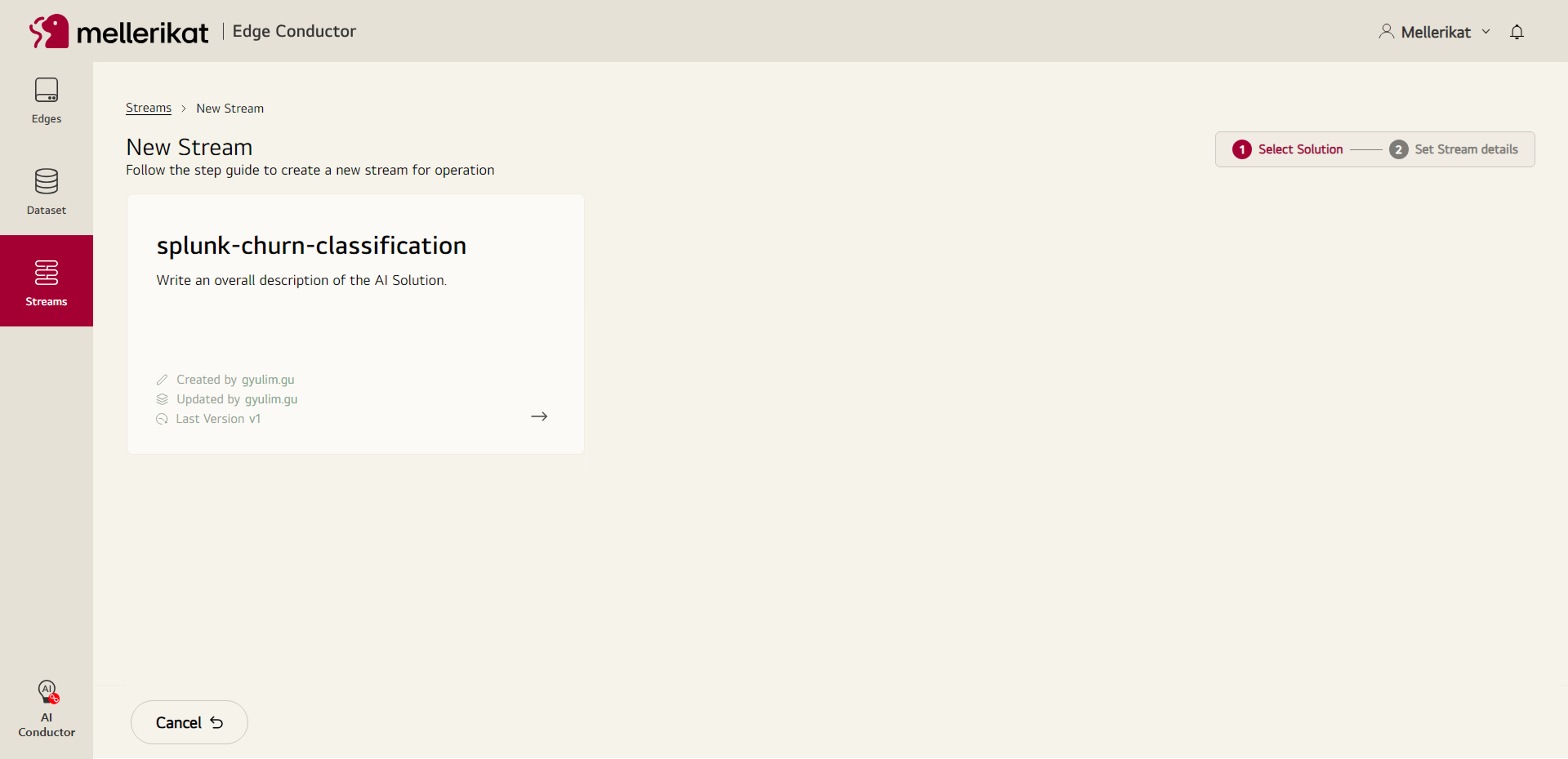
- 학습에 필요한 설정값을 입력 후 Stream 생성을 마칩니다.
- Stream Name: 생성할 Stream의 이름 * required
- Description: 생성할 Stream의 설명
- Tag: Stream에 부여할 태그 정보
- AI Solution: 학습 Parameter 설정
- Inference Warning Setting: 모델 성능 경고를 위한 하한선 설정
- 생성한 Stream에서 Train 버튼을 누르고 사용할 Dataset을 선택하여 학습을 진행합니다.
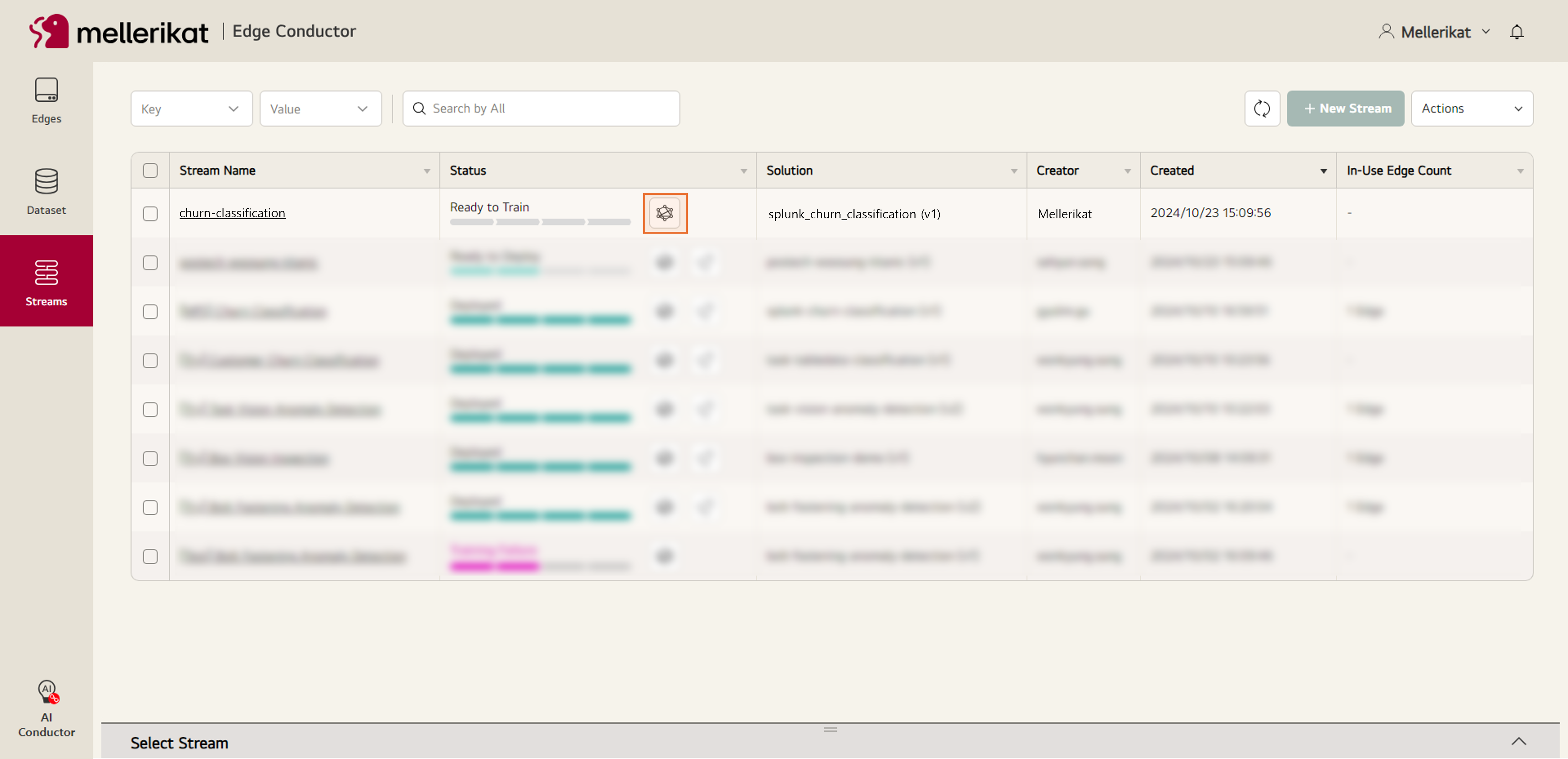
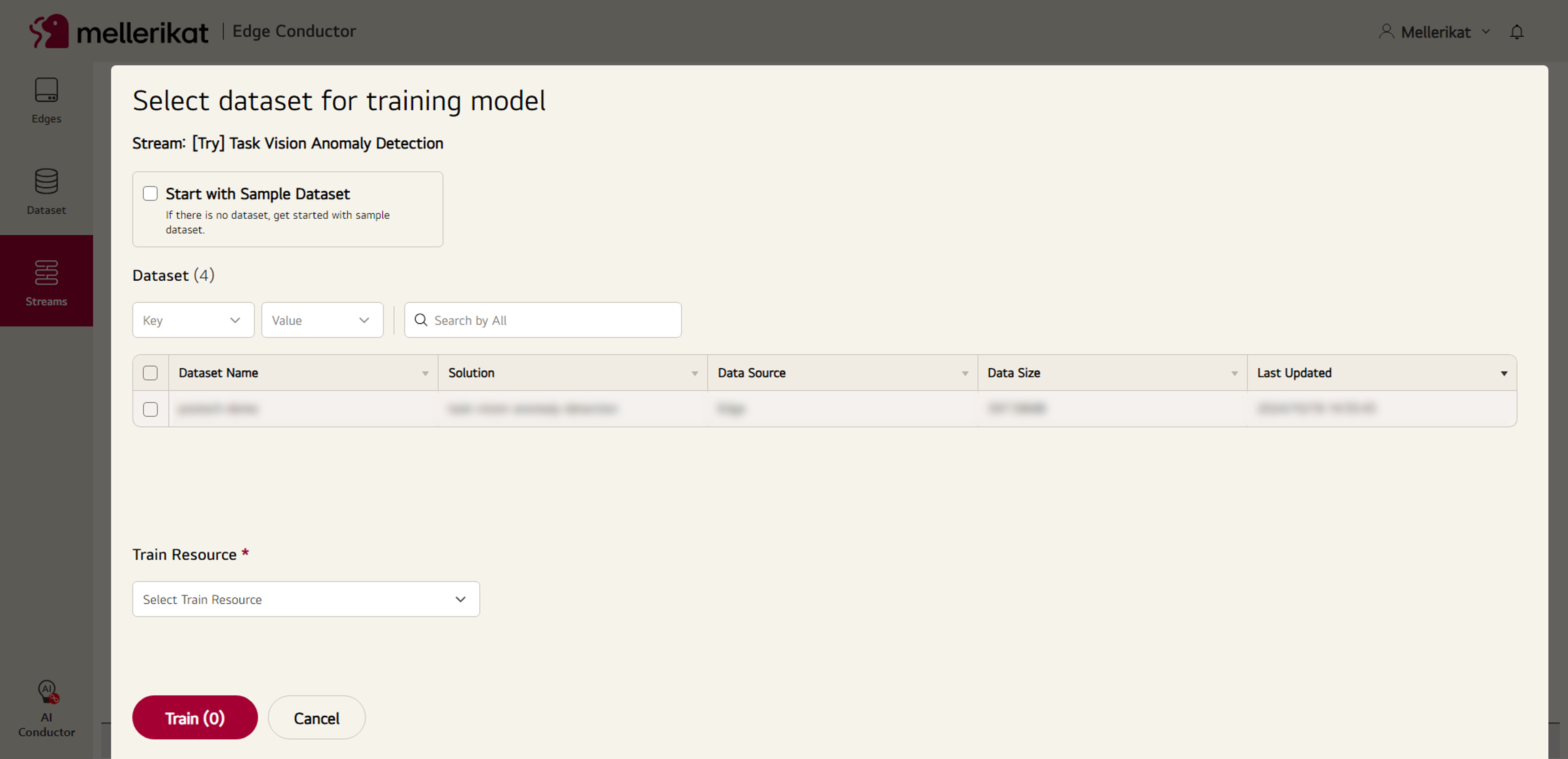
- 학습이 완료되면 설치된 Edge App에 모델을 배포합니다.
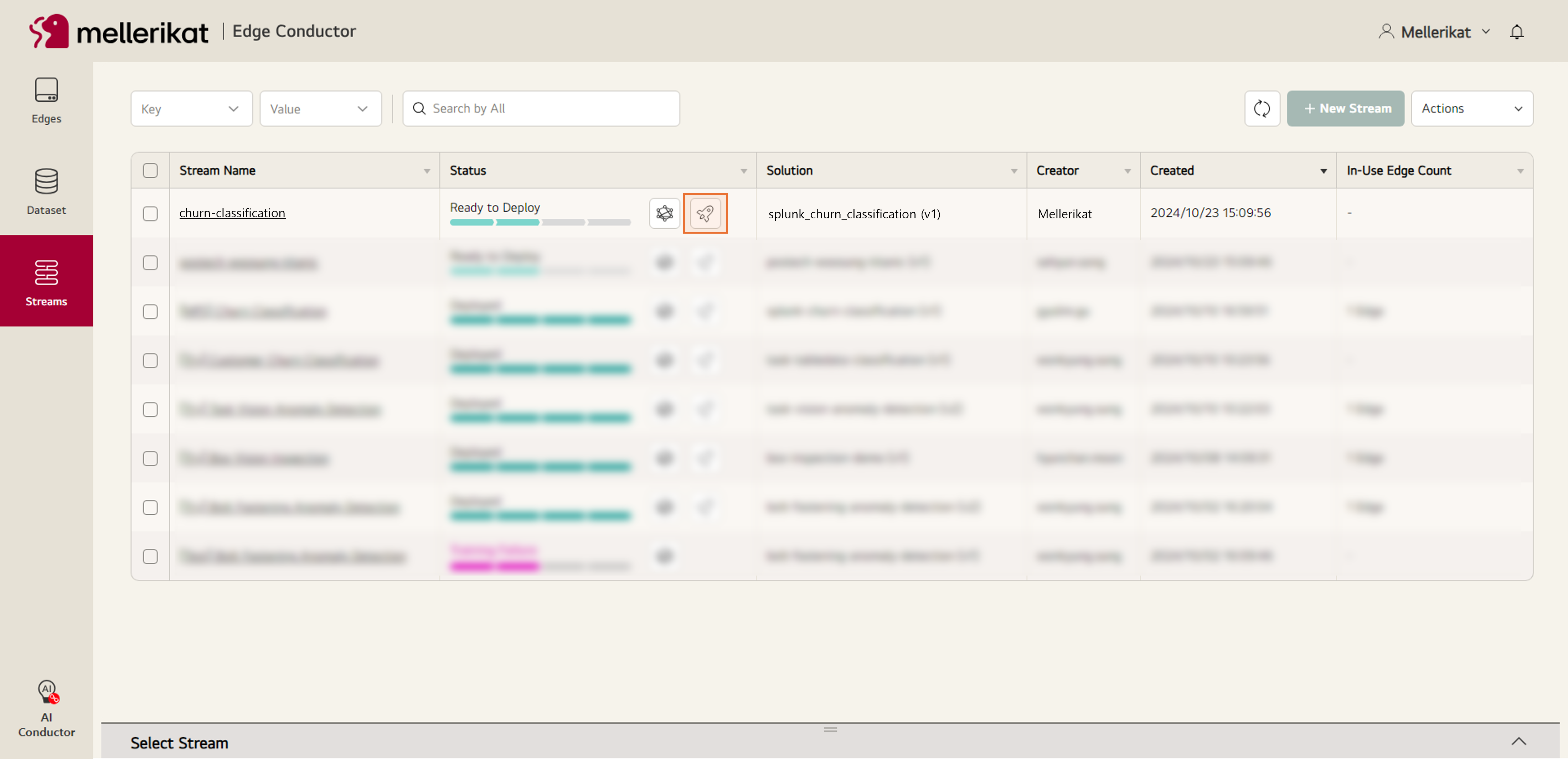
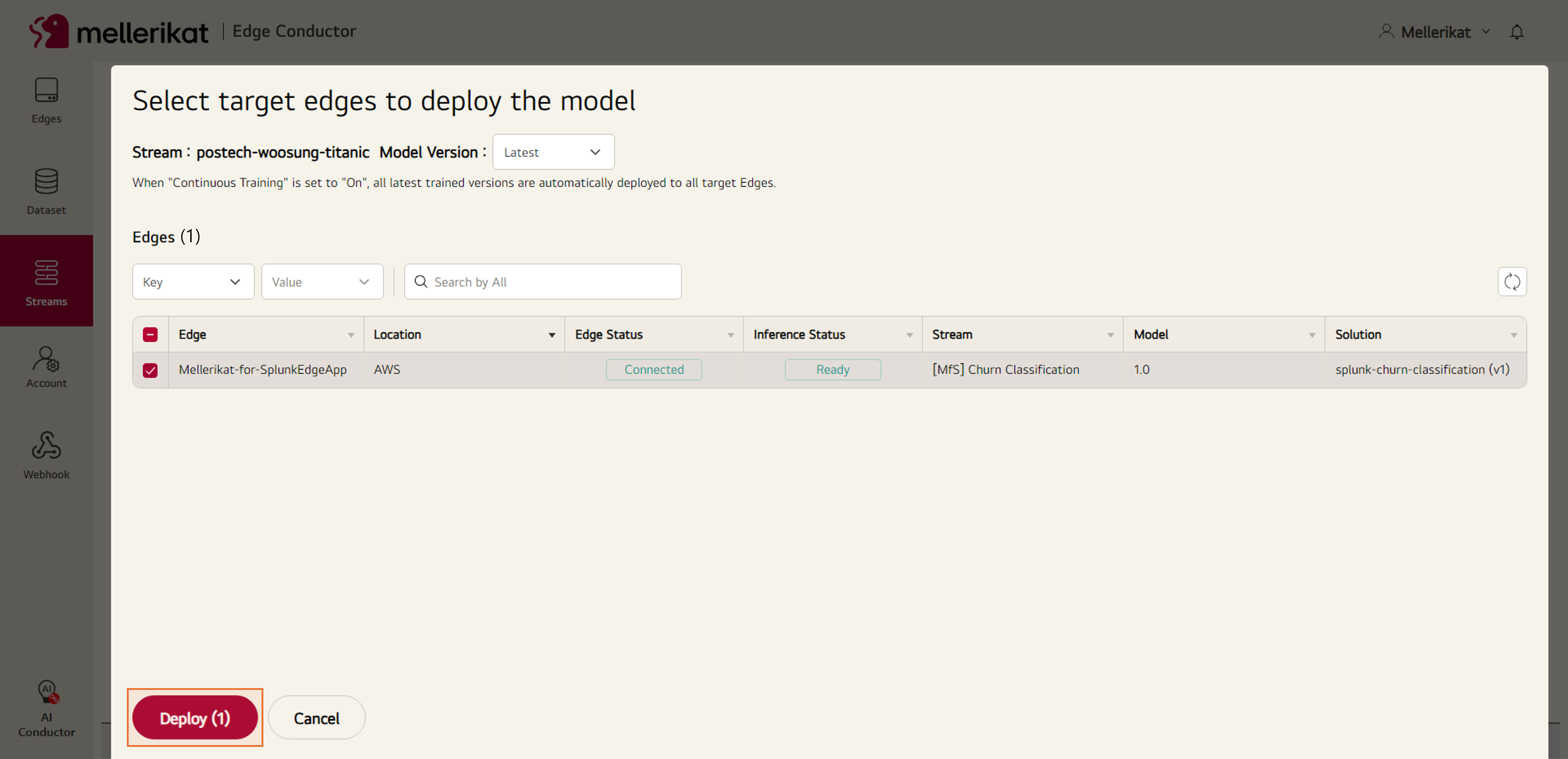
- 모델이 정상적으로 배포되어 Stream의 Status가 Deployed가 되었는지 확인합니다.
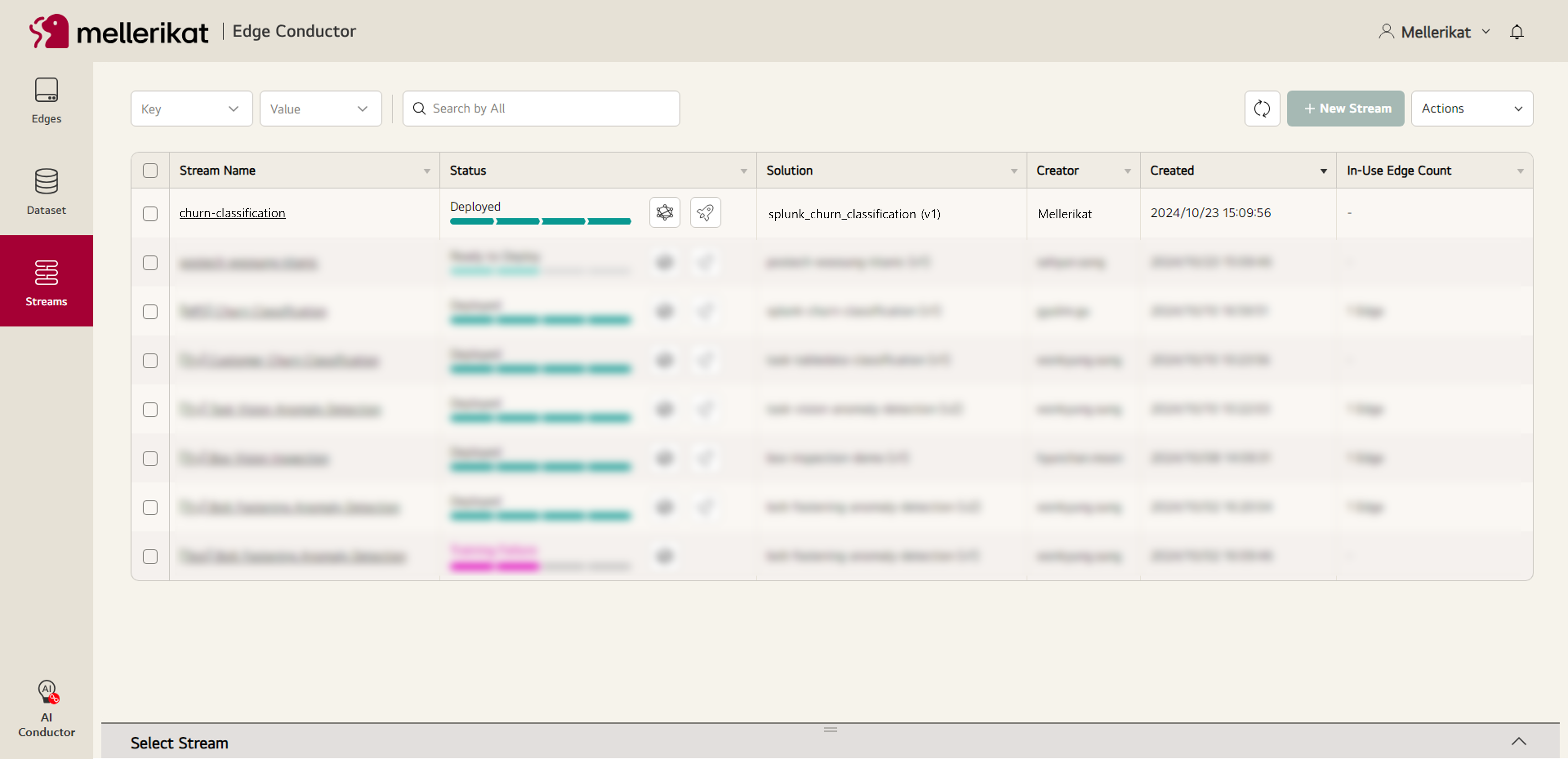
5. Inference 수행
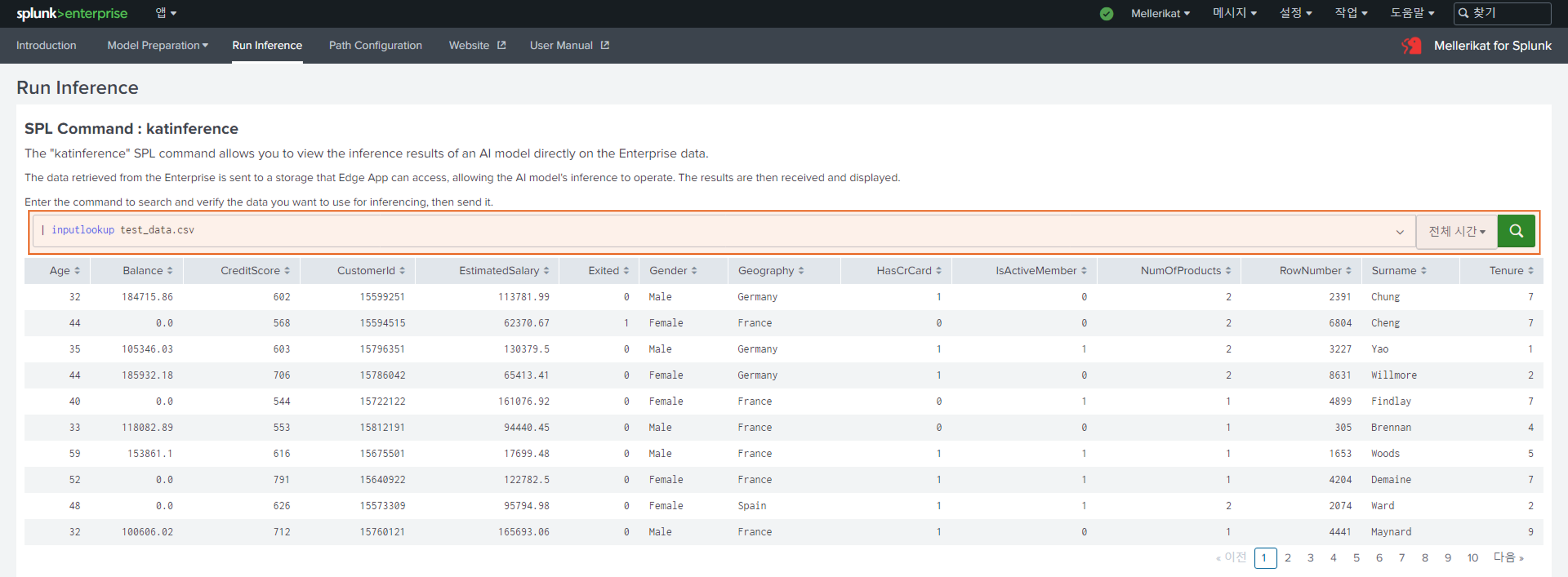
- Inference 탭으로 들어와 Inference를 수행할 데이터를 확인합니다.
- Request Inference 버튼을 눌러 추론된 결과값을 확인합니다.
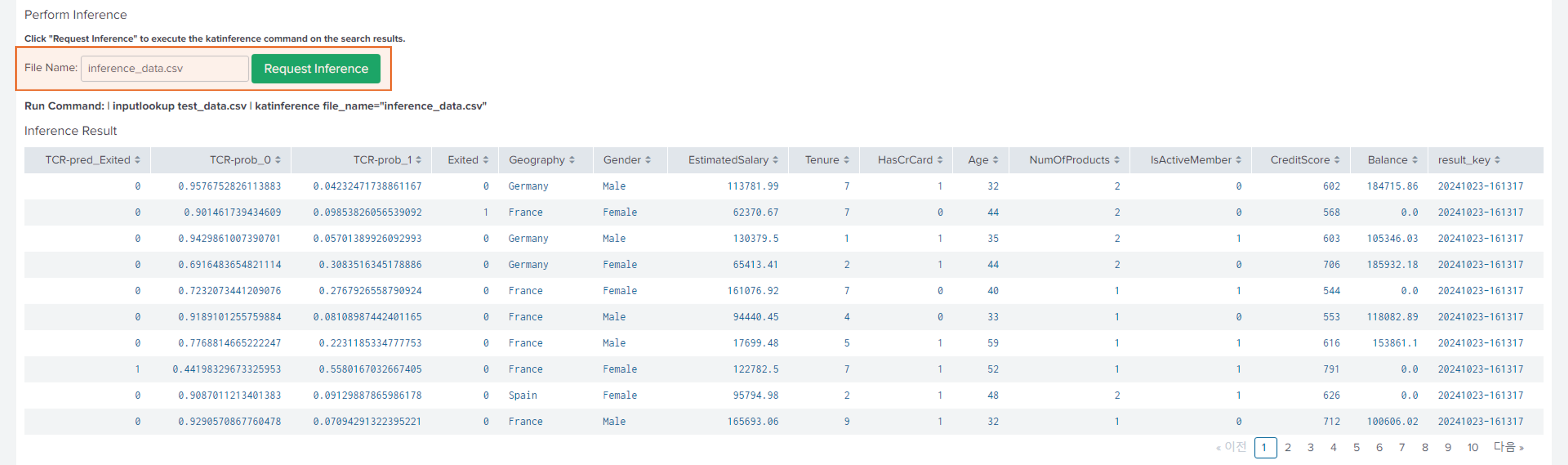
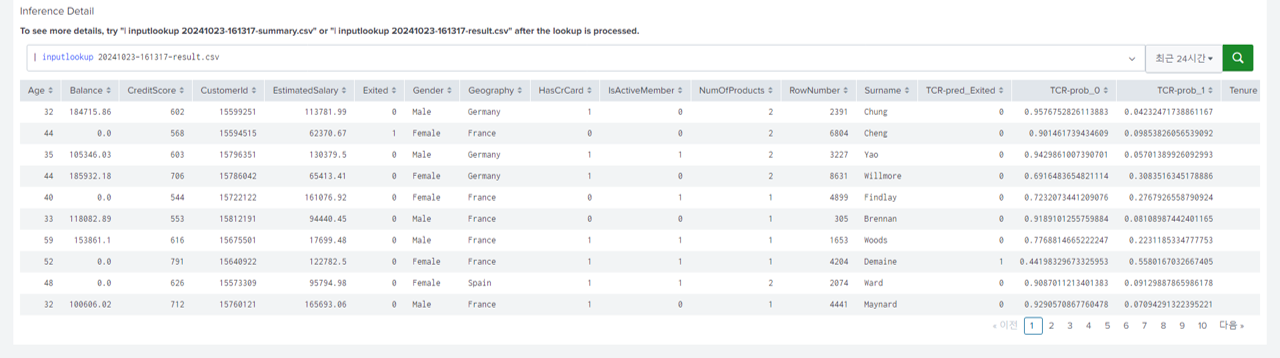
- Inference Detail 부분에서 Inference된 결과값을 확인합니다. Inference Detail은 두 가지 방법으로 조회가 가능합니다.
- 전체 요약 확인

- 개별 결과 확인