Dataset
Dataset은 AI 모델의 학습을 위한 중요한 도구로, 사용자는 다양한 형태의 데이터를 관리하고 활용할 수 있습니다. 학습 데이터셋은 정확도 높은 모델을 위한 중요한 요소이며 따라서 시스템은 사용자에게 데이터셋을 구성하고 활용하는데 다양한 도구들을 제공합니다. 생성된 데이터셋들은 향후 스트림 메뉴에서 학습할 때 사용자에 의해 선택되어지며, 하나 이상의 데이터셋을 학습 데이터로 활용할 수 있습니다.
소스
사용자는 다양한 소스로부터 데이터셋을 생성할 수 있습니다. Edges 추론 결과 데이터, PC 파일 업로드, 그리고 S3 위치한 오브젝트 중의 하나를 사용자는 선택할 수 있습니다. 특히 S3 오브젝트인 경우, 파일을 Edge Conductor 시스템 내로 복사하지는 않고 S3에 있는 채 학습 데이터로 활용하여, Edge Conductor 안에서 별도 저장공간을 부여받지 않습니다.
데이터타입
정형데이터와 비정형데이터를 지원합니다. Dataset을 생성할 때 사용자는 Solution을 선택하며, 선택된 솔루션에서 지원하는 데이터타입을 지원합니다. 정형데이터 데이터셋인 경우, 사용자는 테이블 형태의 데이터를 시각적으로 확인할 수 있으며, 비정형 이미지데이터인 경우 이미지뷰어를 통해 데이터를 확인할 수 있습니다.
솔루션
각각의 데이터셋에는 하나의 AI 솔루션이 정의되어야 합니다. 스트림에서 모델학습 과정 학습데이터셋을 선택할 때, 동일한 AI솔루션이 매핑되어 있는 데이터셋들은 함께 선택될 수 있습니다. 이는 동일한 AI솔루션 모델이 배포된 Edges로부터 추론된 데이터들은, 서로 다른 Edges의 추론 데이터라도 AI솔루션이 같다면 함께 학습데이터로 활용될수 있음을 가능하게 합니다.
편집
데이터셋에는 하나 이상의 데이터파일들이 저장되어 있으며, 데이터셋 생성 이후에도 사용자는 파일을 삭제할 수 있습니다.
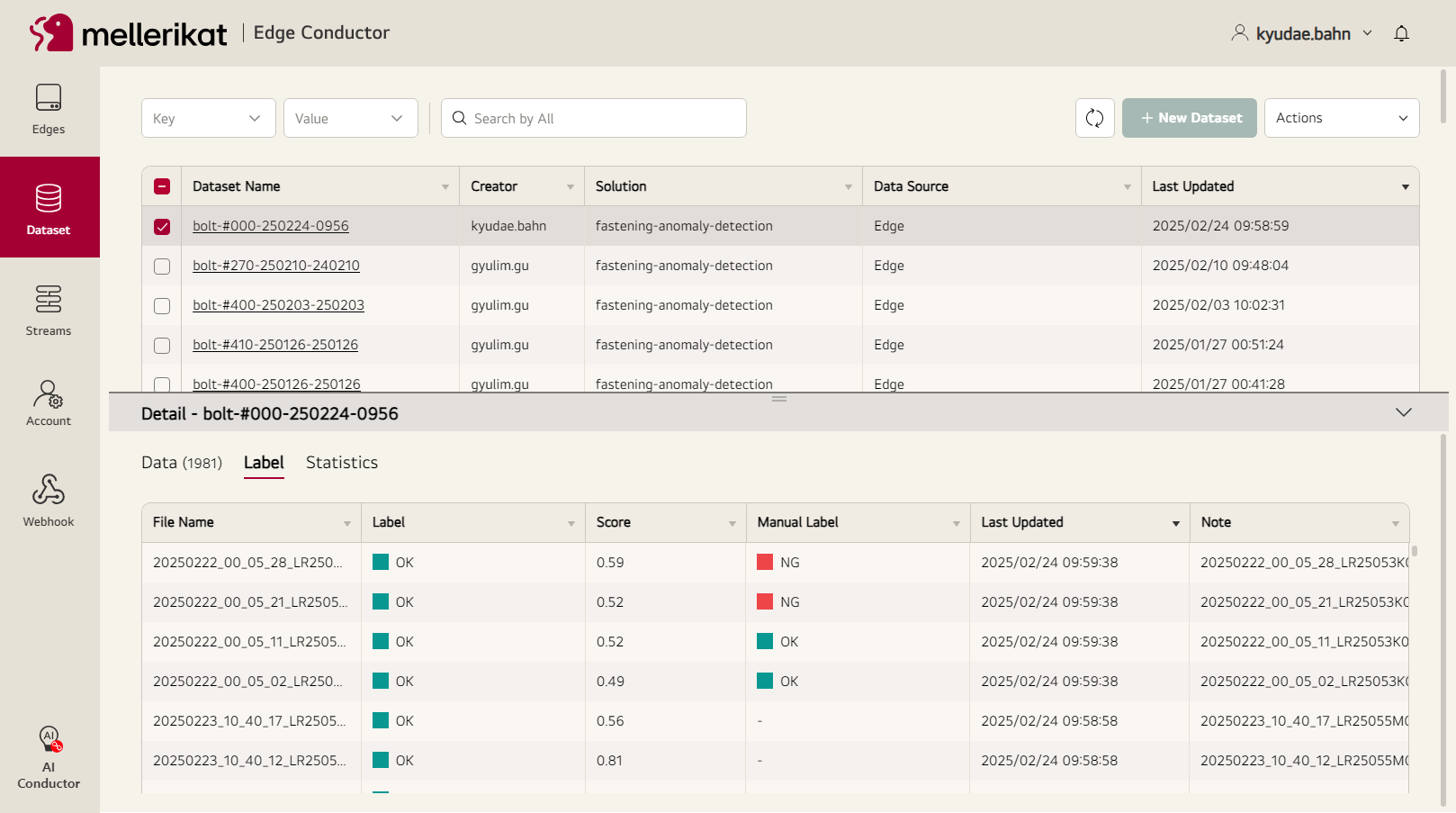
리레이블링
사용자는 데이테셋의 데이터를 확인하며 Relabeling 기능을 할 수 있습니다. 이미지 데이터에 한합니다. 잘못 태깅되어 있는 학습할 데이터의 태깅값을 수정하여, 신뢰성 있는 모델의 성능위하여 정확도 높은 데이테셋을 유지할 수 있도록 합니다. Manual Label과 마지막 수정날짜는 시스템은 제공하며, 이를 통해 사용자는 해당 값이 태깅 히스토리를 확인할 수 있습니다. 각각의 데이터에는 Score 값을 함께 제공하며, 사용자는 Score 값이 낮은 데이터를 선별적으로 우선순위를 두어 레이블 대상 데이터로 활용할 수도 있습니다. 필요한 경우 데이터셋 복제 기능을 활용할 수 있습니다. 이미 모델학습에 활용된 데이터셋인 경우 그 데이터셋을 변경없이 유지하고 싶을 수 있습니다. 이때 데이터셋을 복제(relabel 메뉴에서 Save As) 기능을 통해서 특정 데이터셋은 relabel 변경없이 빌드활용상태를 유지할 수 있습니다.