Observability
AI services today are no longer just about development; their competitiveness depends on how they work and how efficiently they operate. Observability integrates LangSmith and LangFuse into a single wrapper, enabling precise tracking from execution logs to response quality and allowing analysis of the entire flow and bottlenecks of LLM services. And it doesn’t stop there. It extends beyond operations into intelligence, offering FAQ recommendations, prompt optimization, and intelligent suggestions.
Service Scenario
From Data Collection to Intelligence
A powerful service partner that connects operational workflows, interprets data, and autonomously improves the quality of AI services
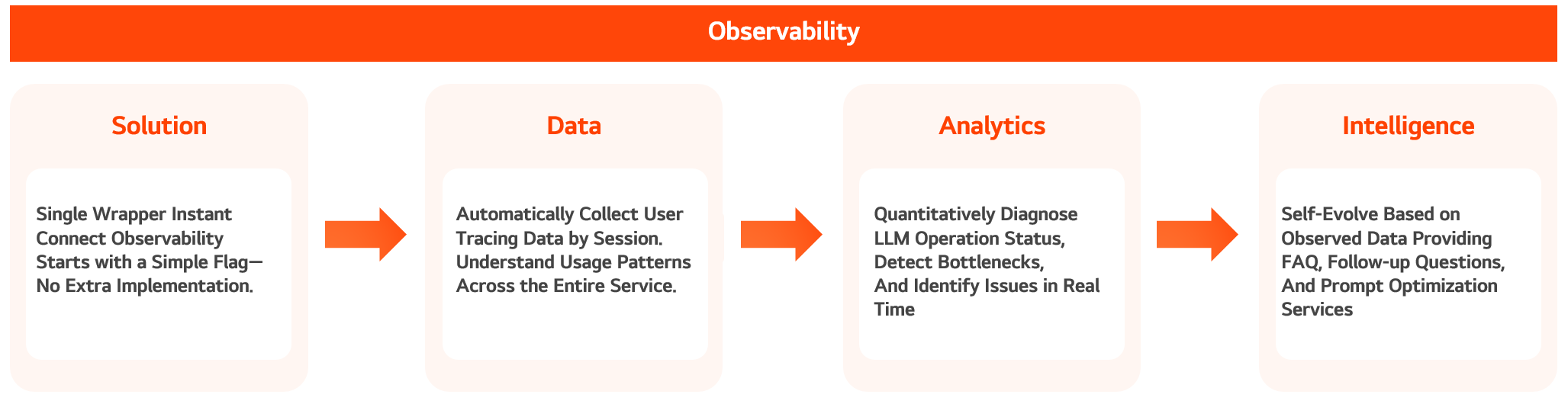
Solution
Seamless Compatibility – Freely switch between LangFuse and LangSmith with a single Wrapper
The provided Wrapper enables seamless switching between LangSmith and LangFuse with just a single flag setting. Without any separate implementation for each LLM logic, observability integration is completed with a single decorator. You can add observability features to your existing services instantly, without complex configurations. Now, you can be ready to collect and analyze execution flows in just a few minutes.
Observability Tracing Data
Standardized Data Hub – Precisely capturing the entire LLM service flow on a session-by-session basis
Observability is not just a system for storing logs. We integrate and collect all execution elements—such as execution logs, prompts, responses, and user feedback—in a standardized format, structuring them by session so that the entire LLM service execution flow can be understood as a single coherent context.
Beyond observing individual agents, we refine execution patterns and response contexts across the entire service into an analyzable structure. This structure forms the foundation for subsequent analysis and intelligence features.
Analytics
Real-Time Analysis and Operational Diagnostics Based on Collected Data
Collected data is processed into real-time operational metrics. From session-based flows, latency, token usage, response quality, and cost are extracted and visualized on monitoring dashboards. - Automatically detect speed bottlenecks by measuring the time from request to response - Analyze resource consumption based on token usage and pricing information - Evaluate response quality using user feedback and response relevance Going beyond simple monitoring, this enables rapid identification of problem areas and optimization of operational costs.
Intelligence
Extending Execution Data into Intelligence
Based on the observed data, AI autonomously recommends questions. Leveraging the collected and analyzed observability data, it automatically suggests frequently asked questions (FAQs), generates related queries, and provides prompt recommendations to improve the service—expanding into an intelligent feature set. This functionality goes beyond simple recommendations by analyzing correlations among actual user question logs, responses, and feedback to derive the most meaningful questions. These intelligence features are integrated as plugins into the chatbot interface of agents in operation, allowing automatic recommendations to be toggled on or off with a single button.
Automated FAQ Recommendation Service
Why Observability, Now?
Equipping operations with visibility is no longer optional but essential. - The quality of LLM services can no longer be explained by qualitative evaluation alone. - Every aspect—from operational flow and resource consumption to user reactions—is quantified. - Only AI services capable of automated decision-making based on quantified data can scale effectively.
Service Architecture
Data Flow and Intelligent Expansion Architecture of Observability-Centered AI Services
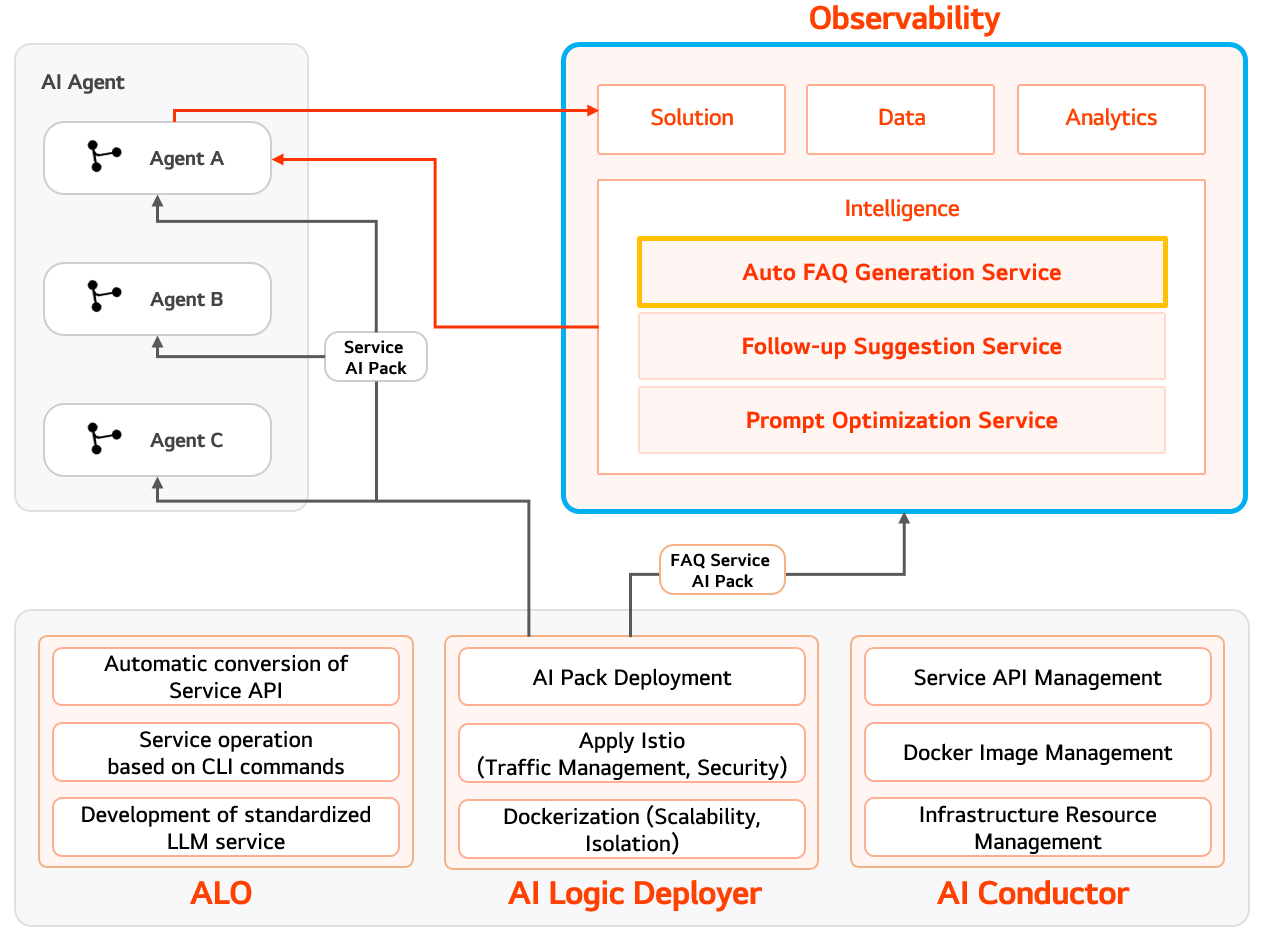
Observability serves as a central hub that collects and analyzes all execution data generated by AI agent services, enabling real-time monitoring and the expansion of intelligent features based on this data. Prompts, responses, and user feedback generated at the agent level are delivered to Observability in a standardized format through a wrapper. The data is then refined and analyzed on a session basis through the Solution → Data → Analytics stages. The generated data extends into intelligent services such as Auto FAQ Generation, Follow-up Suggestions, and Prompt Optimization, which feed back into the agents and are applied as plugins directly within the chatbot interface.
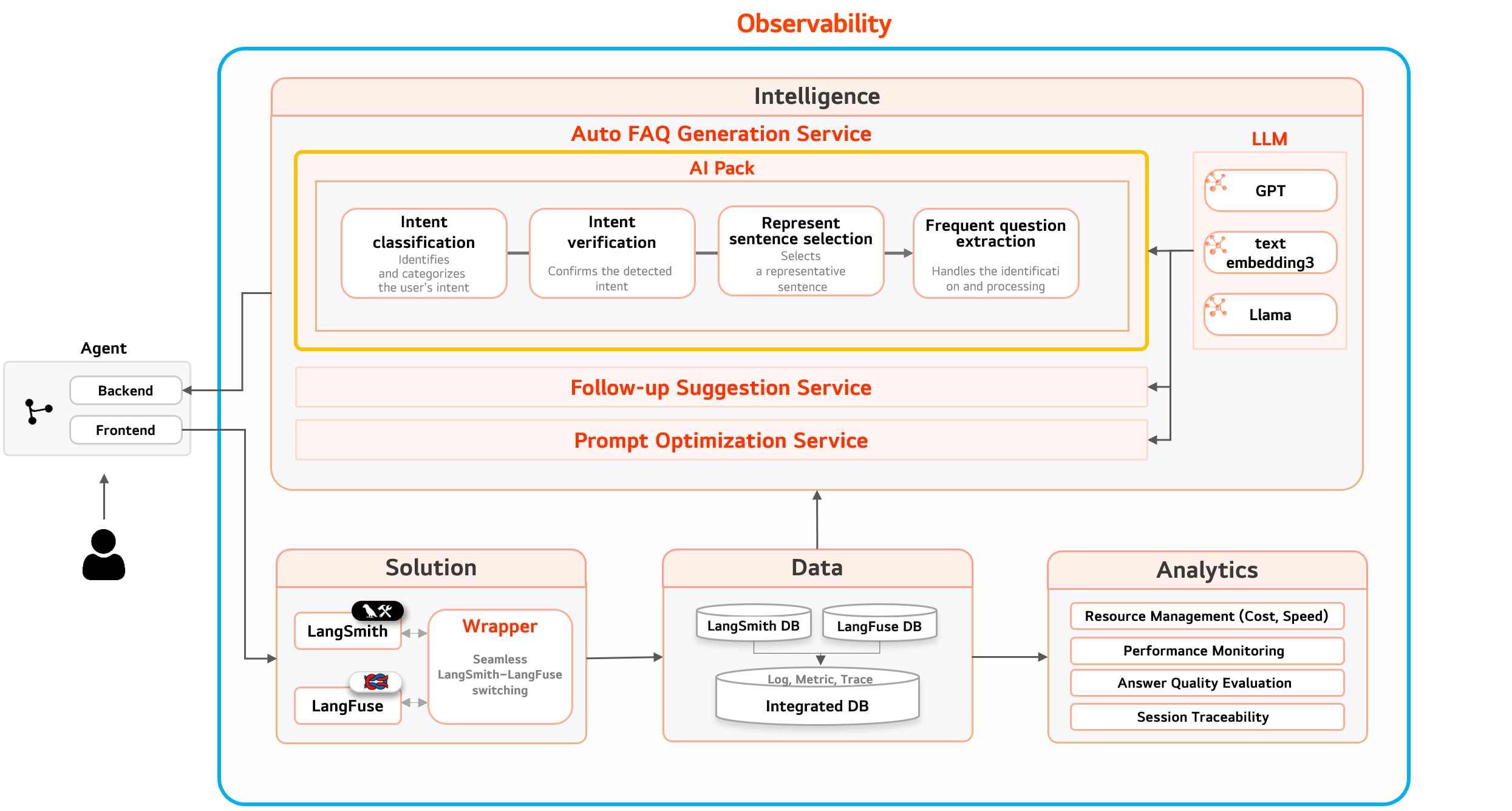
The overall architecture connects reliably to infrastructure environments such as Docker, Istio, and APIs through the AI Logic Deployer and AI Conductor, ensuring both scalability and operational efficiency.
Need AI Services?
Consult with mellerikat experts
For detailed information on using mellerikat, please refer to the user manual.
