TCR Features
기능 개요
TCR의 pipeline
AI Contents의 pipeline은 기능 단위인 function의 조합으로 이루어져 있습니다. Train pipeline, Inference pipeline은 모두 5개의 step으로 구성되어있습니다.
Train pipeline
Input - Readiness - Preprocess - Sampling - Train
Inference pipeline
Input - Readiness - Preprocess - Sampling - Inference
Input step
사용자가 experimental_plan.yaml에 지정한 경로 내 파일을 읽어와 dataframe으로 만들어 줍니다.
Readiness step
사용자가 TCR에 입력한 데이터가 TCR 모델링에 적합한지 검사합니다.
Preprocess step
데이터에 categorical 컬럼 인코딩, 결측치 처리 등 TCR 모델링을 위한 데이터 전처리 방법 적용합니다.
Sampling step
데이터 라벨에 불균형이 있는 경우, over sampling 혹은 under sampling을 적용하여 데이터의 균형을 맞춥니다.
Train step
TCR에 내장 된 5개의 모델로 HPO를 진행하고, best model을 선정하여 모델을 학습한 후 산출물을 반환합니다.
Inference step
Train step에서 생성한 모델로 inference용 데이터를 추론한 후 산출물을 반환합니다.
사용 팁
TCR의 auto mode 진행 후 로그 파일 확인
데이터 경로와 X 컬럼, Y 컬럼 정보만 experimental_plan.yaml에 입력한 후 alo를 실행하면 TCR이 알아서 입력한 데이터에 대한 검사, 전처리를 진행합니다. 이후 로그 파일을 확인하면 아래 항목을 확인할 수 있습니다. 로그 파일은 'workspace/tcr/log/process.log'입니다. process.log에서는 각 function별 출력 로그를 확인할 수 있습니다. 아래 이미지는 TCR 실��행 시 Readiness function에서 생성되는 생성되는 log 예시입니다. pipeline.log에서는 각 step별 출력 로그를 확인할 수 있습니다.
# TCR의 train_dataset/train.csv의 titanic 데이터의 readiness function 실행 결과 입니다.
***************************** Invoke Pipline Function *****************************
* Target File : /home/gy90.moon/tcr_v3_check3/pipeline.py
* function[name] : readiness
* function[name].def : pipeline.readiness
* function[name].argument : {'x_columns': ['input_x0', 'input_x1', 'input_x2', 'input_x3'], 'y_column': 'target', 'task_type': 'classification', 'target_label': '_major', 'column_types': 'auto'}
* summary :
***********************************************************************************
[2025-04-30 00:23:10,257|root|DEBUG|logger.py(182)|decorator()] -------------------- Finish readiness pipline(0.02)
[2025-04-30 00:23:10,257|root|DEBUG|logger.py(173)|decorator()] -------------------- Start preprocess pipline
[2025-04-30 00:23:10,883|root|DEBUG|pipeline.py(95)|preprocess()] preprocess
[2025-04-30 00:23:10,883|root|INFO|preprocess.py(537)|save_info()] categorical_columns: []
[2025-04-30 00:23:10,883|root|INFO|preprocess.py(537)|save_info()] numeric_columns: ['input_x0', 'input_x1', 'input_x2', 'input_x3']
[2025-04-30 00:23:10,887|root|INFO|preprocess.py(537)|save_info()] shape of input data before filtering: (147, 10)
[2025-04-30 00:23:10,887|root|INFO|preprocess.py(537)|save_info()] shape of input_data after filtering: (147, 10)
[2025-04-30 00:23:10,889|root|INFO|preprocess.py(537)|save_info()] non_groupkey dataframe missing rate: 0.0
[2025-04-30 00:23:10,889|root|ERROR|preprocess.py(545)|save_error()] There seems to be an issue with creating the folder path: /home/gy90.moon/tcr_v3_check3/.workspace/tcr/model_artifacts. Please check if the path is correct and accessible.
[2025-04-30 00:23:10,891|root|INFO|tabular_preprocess.py(403)|save_info()] >>>>> Starting missing value handling (handle_missing).
[2025-04-30 00:23:10,891|root|INFO|tabular_preprocess.py(403)|save_info()] Applying median missing value handling methodology to the ['prep_input_x0', 'prep_input_x1', 'prep_input_x2', 'prep_input_x3'] column(s).
[2025-04-30 00:23:10,891|root|INFO|tabular_preprocess.py(403)|save_info()] >>>>> Starting the categorical encoding process.
[2025-04-30 00:23:10,900|root|INFO|tabular_preprocess.py(403)|save_info()] >>>>> Starting missing value handling (handle_missing).
[2025-04-30 00:23:10,900|root|INFO|tabular_preprocess.py(403)|save_info()] Applying drop missing value handling methodology to the ['prep_target'] column(s).
[2025-04-30 00:23:10,902|root|INFO|tabular_preprocess.py(403)|save_info()] >>>>> Starting the categorical encoding process.
[2025-04-30 00:23:10,902|root|INFO|tabular_preprocess.py(403)|save_info()] Applying label encoding methodology to the ['prep_target'] column(s).
[2025-04-30 00:23:10,910|root|WARNING|alo.py(804)|make_summary()] [PIPELINE] Missing 'summary' key in 'preprocess' function result. Creating default summary.
[2025-04-30 00:23:10,910|root|WARNING|alo.py(814)|make_summary()] [PIPELINE] Missing required keys ['note', 'result', 'score'] in summary dict. Adding default values.
- Readiness의 컬럼 유형 분류 결과 확인
- ALO 구동 후 입력한 x 컬럼이 numeric, categorical 컬럼으로 잘 분류 되어있는지 로그를 확인합니다.
- 만약, 컬럼이 잘못 분류되어 있다면, readiness의 user argument column_types에 잘못 분류 된 컬럼을 입력하여 컬럼 유형을 지정해 줍니다.
- Readiness의 cardinality 검사 결과 확인
- TCR에서는 categorical 컬럼의 경우 catdinality(default: 50) 조건을 걸어, categorical 데이터의 category수가 cardinality 조건을 넘으면 학습 컬럼에서 제외합니다. 위와 같이 cardinality 조건에 맞지 않는 컬럼은 x_columns에서 제외한다는 로그가 출력됩니다.
- 만약, 사용하는 categorical 데이터의 cardinality가 default 값인 50 보다 높으면, readiness의 user argument cardinality를 수정해 주세요
큰 데이터 사용시 �메모리 최소화 방법
TCR 사용시 categorical encoding 전처리, HPO를 위한 data split 방법론 적용, over sampling 적용에 따라 step에서 다음 step으로 전달되는 데이터의 양이 많아집니다. 파일 사이즈가 큰 데이터를 사용하는 경우, 아래와 같이 세팅하면 메모리 사용량을 줄일 수 있습니다.
- Preprocess: categorical encoding 방법론을 catboost 변경
- default categorical encoding 방법론은 binary encoding으로 되어 있습니다. binary encoding의 경우 onehot 인코딩보다는 cateogory 수가 크게 증가하지 않지만, categorical 데이터가 많고 cardinality가 매우 클수록 데이터가 커질 수 있습니다. 따라서 user argument인 categorical_encoding: {catboost: all}을 세팅하여 categorical encoding을 catboost encoding으로 지정하면 컬럼이 늘어나는 것을 막을 수 있습니다.
- Sampling: data split 방법론을 train test split으로 변경
- Sampling step에서 train step으로 전달하는 결과물은 재학습에 사용할 전체 dataframe과 HPO를 위한 dataset list 2가지 입니다.
- cross validation을 사용할 경우 fold 수 만큼 데이터가 복사 되어 다음 step으로 넘어갑니다.
기능 상세
Train pipeline: Input step
Input step에서는 experimental_plan.yaml에 지정한 사용자 데이터 경로의 모든 파일을 가져와 읽어 하나의 dataframe으로 만들어 줍니다. 사용자 데이터 경로는 experimental_plan.yaml의 dataset_uri에 train/inference 별로 입력합니다. 이때 데이터 경로는 파일 명을 제외한 폴더 경로여야 합니다. 예를 들어, Train pipeline에서는 train 항목의 dataset_uri 경로의 데이터를 불러옵니다.
train:
dataset_uri: [train_dataset/] # 데이터 폴더, 폴더 리스트 (파일 형식 불가)
inference:
dataset_uri: inference_dataset/
- 사용자가 입력한 경로 하위에 폴더가 있는 경우, 해당 폴더 안의 데이터도 모두 읽어와 하나로 합칩니다.
- 사용자가 입력한 경로 하위에 있는 모든 파일은 컬럼이 동일해야 합니다.
- experimental_plan.yaml에 대한 자세한 설명과 input function parameter에 대한 설명은 다음 가이드를 참고해 주세요 TCR Parameter 가이드
Train pipeline: Readiness step
Readiness step에서는 사용자가 학습/추론에 사용하는 데이터가 TCR 모델링에 적합한지 검사합니다. Readiness step은 train pipeline과 inference pipeline마다 필요한 검사를 진행하며 각 pipeline 별로 검사하는 상세 항목은 아래와 같습니다.
검사 목록
- experimental_plan.yaml에 작성한 컬럼 명이 데이터 내 존재하는지 검사
readiness step에서 사용자가 입력하는 컬럼명 항목은 아래와 같습니다. readiness step은 아래 arguments에 대해서 사용자가 dataframe에 있는 컬럼 명을 입력했는지 검사합니다. 각 arguments의 자세한 사용법은 TCR Parameter 가이드를 참고해주세요.
- x_columns: 학습 대상 컬럼
- y_column: 라벨 컬럼
- groupkey_columns: 입력한 컬럼의 value 값을 기준으로 dataframe을 grouping진행.
- drop_x_columns: dataframe 전체 컬럼을 학습 대상 컬럼으로 하고, drop_x_columns에 입력한 컬럼을 제외하여 학습 대상 컬럼으로 지정. x_columns에 넣을 컬럼 명이 많을 경우 대신 사용
Readiness step에서는 groupkey 기능을 제공합니다. groupkey 기능은 특정 컬럼의 값 기준으로 데이터를 grouping하여 분석하는 방식입니다. 아래와 같은 표가 있을 때, 'groupkey col'을 그룹키 컬럼으로 지정하면 'groupkey col' 컬럼 값이 A인 데이터와 B인 데이터 각각 모델링이 진행됩니다. 이때, 'groupkey col'은 groupkey column, A,B는 groupkey가 됩니다. groupkey_columns argument를 사용하면 groupkey 기능을 사용할 수 있습니다.
| x0 | ... | x10 | groupkey col |
|---|---|---|---|
| .. | .. | .. | A |
| .. | .. | .. | A |
| .. | .. | .. | B |
| .. | .. | .. | B |
| .. | .. | .. | A |
- user arguments 조합 검사
함께 쓰일 수 없는 user arguments에 대해 검사하고 사용자가 arguments를 잘못 입력한 경우, 에러를 발생시켜 pipeline 진행을 중단합니다.
- x_columns에 groupkey_columns의 컬럼이 들어있으면 에러 처리합니다.
- x_columns에 y_column이 들어있으면 에러 처리합니다.
- x_columns와 except_x_columns 동시에 컬럼 값이 있으면 에러 처리합니다.
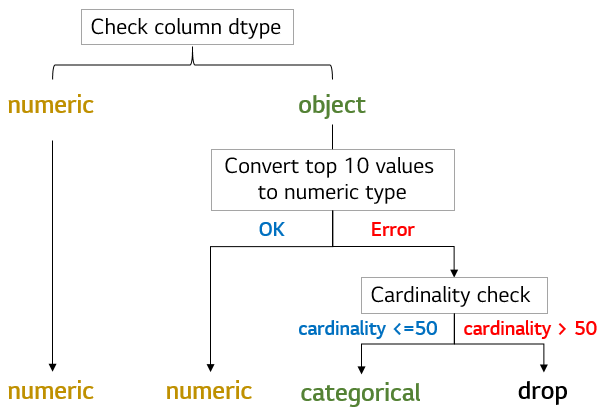
- x 컬럼의 컬럼 유형 조사 readiness step에서는 사용자가 지정한 x 컬럼이 categorical 컬럼 혹은 numeric 컬럼인지 내장 된 기본 로직을 통해 조사합니다. readiness step에서 categorical/numeric 컬럼을 분류하면 다음 preprocess step에서 categorical 컬럼과 numeric 컬럼에 맞는 전처리 방법론을 적용합니다. 아래 이미지의 분류 알고리즘을 통해 readiness step은 컬럼 유형을 분류합니다. 자동 분류 알고리즘에서 컬럼의 유형이 잘못 분류 될 경우, 잘못 분류 된 컬럼에 대해서는 사용자가 readiness step의 user argument인 column_types를 수정하여 일부 컬럼은 categorical 혹은 numeric 컬럼으로 분류하도록 지정할 수 있습니다. 또한 위 로직의 '자주 등장하는 topN 형변환'은 num_cat_split arguments를 yaml 파일에 수정하여 default 로직을 수정할 수 있습니다.
- train시 학습에 필요한 최소 데이터 수 검사 classification 혹은 regression 모델링 시 필요한 최소 데이터 수가 확보되지 않으면 readiness step은 에러를 발생시켜 pipeline 진행을 중단합니다. 이는 최소 모델링 성능을 보장하기 위함입니다. 현재 기본 로직은 아래와 같습니다.
- classification일 경우
- y 컬럼의 label 별 최소 데이터 수가 30개 이상인지 확인합니다.
- regression
- 전체 데이터 수가 최소 100개 이상인지 확인합니다.
user arguments인 min_rows를 사용하여 데이터 학습에 필요한 최소 데이터 수 값을 수정할 수 있습니다.
<groupkey 기능 사용 시> 학습에 필요한 최소 데이터 수 검사가 groupkey 별로 적용됩니다. 일부 groupkey는 학습 조건을 만족하지 못하지만, 일부 학습 가능한 groupkey가 있으면 readiness step은 에러를 발생시키지 않고 학습 가능한 groupkey 데이터만 다음 step으로 전달합니다. 그리고 전체 groupkey가 학습 조건을 만족하지 않을 경우 에러를 발생시킵니다.
- y 컬럼 단일 값 구성 여부 검사 y 컬럼이 하나의 값으로 구성되면 모델링을 할 수 없기 때문에, readiness step은 y 컬럼이 하나의 값으로만 이루어져 있으면 에러를 발생시킵니다.
- x 컬럼 결측치 검사 x 컬럼으로 지정된 컬럼 중 데이터가 전부 결측치로 구성되어 있으면 해당 컬럼은 x 컬럼에서 제외합니다.
<groupkey 기능 사용 시> groupkey 기능을 사용하는 경우 일부 groupkey에서 특정 컬럼이 전부 결측치로 구성되는 상황이 발생할 수 있습니다.
| x0 | ... | x10 | groupkey col |
|---|---|---|---|
| .. | .. | 1 | A |
| .. | .. | 2 | A |
| .. | .. | NaN | B |
| .. | .. | NaN | B |
| .. | .. | 2 | A |
위와 같은 경우에는 컬럼 'x10'을 삭제하지 않고, groupkey B의 'x10' 컬럼을 전부 아래와 같은 로직으로 채워 줍니다.
- 결측 컬럼이 categorical 컬럼일 경우
- x10의 가장 많은 값(frequent)으로 그룹키 B 컬럼의 결측치를 채웁니다.
- 결측 컬럼이 numeric 컬럼일 경우
- x10의 median 값으로 그룹키 B 컬럼의 결측치를 채웁니다.
- groupkey 컬럼 기능 사용 시 y 컬럼 class 수 검사 groupkey 컬럼을 사용할 경우, 모든 groupkey의 y 컬럼 class 종류가 동일해야 합니다. 즉, groupkey A의 y 컬럼 class 종류와 B의 y 컬럼 class 종류가 동일해야 합니다. 해당 조건을 만족하지 않는 groupkey는 학습 대상 groupkey에서 제외됩니다.
Train pipeline: Preprocess step
Preprocess step에서는 학습 데이터에 데이터 형 변환 및 전처리 방법론을 적용합니다. Preprocess step에서는 아래 4가지에 대한 전처리를 제공합니다.
- 결측치 처리(argument: handle_missing)
- categorical 컬럼에 적용 가능: frequent(빈도 값 채우기)
- numeric 컬럼에 적용 가능: mean, median, interpolation
- 모든 컬럼에 적용 가능: drop(결측 행 삭제), fill_{값}({값}으로 결측치 채우기)
- categorical encoding(argument: categorical_encoding)
- binary, catboost, onehot, label encoding
- numeric 데이터 scaling(argument: numeric_scaler)
- standard, minmax, robust, maxabs, normalizer
- numeric 데이터 outlier 제거(argument: numeric_outlier)
- normal(현재 데이터 분포에서 3sigma 넘는 이상치를 제거)
Preprocess step은 기본적으로 default 룰이 있으며 readiness step에서 검사한 categorical, numeric 컬럼에 이를 적용합니다. categorical, numeric 철럼에 데이터 형 변환을 적용하고, categorical encoding, 결측치 처리 방법론을 적용합니다. Preprocess step의 default 전처리 룰은 다음과 같습니다.
<x 컬럼에 적용되는 default 전처리>
- 결측치 처리
- categorical 컬럼에는 가장 빈도수가 많은 값으로 채웁니다.(frequent)
- numeric 컬럼에는 중앙값으로 값을 채웁니다.(median)
- categorical encoding
- binary encoding을 적용합니다.
<y 컬럼에 적용되는 default 전처리>
- 결측치 처리
- 결측 행을 제거 합니다(drop).(user arguments로 변경 불가)
- categorical encoding
- label encoding을 적용합니다.(classification시 적용되며, user arguments로 변경 불가)
x 컬럼에 적용되는 default 로직은 yaml파일에 arguments를 추가하여 수정할 수 있습니다. 구체적인 작성 방식은 위 방법론 링크를 눌러 TCR parameter 가이드의 argument 설명을 참고해 주세요. TCR Parameter Guide.
Train pipeline: Sampling step
Sampling step은 크게 두가지 기능을 합니다. 먼저 train step에서 HPO를 위한 데이터 셋을 샘플링하여 만드는 data split 기능과, 불균형 데이터를 처리하기 위한 sampling 방법론 적용입니다.
- Data split
sampling step에서는 train step에서 HPO 진행 시 필요한 데이터 셋을 생성하고 이를 train step으로 전달합니다. 방법론은 cross validation, train test split 두 가지가 있으며, YAML파일에 data_split argument로 변경 가능합니다.
-
cross validation
- HPO를 위해 cross validation 방법론을 사용하여 data를 train set과 validation set으로 분할합니다.
- YAML 파일에 cross validation / 3 fold 옵션이 default 값으로 기입되어있습니다.
[[train_fold1, validation_fold1], [train_fold2, validation_fold2], ...]와 같이 cross validation이 된 데이터가 다음 step으로 전달됩니다.- data split 기능과 sampling 기능을 함께 사용하는 경우 각 fold의 train set에 sampling 방법론이 적용됩니다.
- fold 수 만큼 데이터가 복사 되어 다음 step으로 전달되기 때문에 이를 고려하여 fold 수를 선택해야 합니다.
-
train test split
- Train set과 validation set을 정해진 비율대로 분할합니다.
- data split 기능과 sampling 기능을 함께 사용하는 경우 각 fold의 train set에 sampling 방법론이 적용됩니다.
- [[train set, validation set]]의 형태로 다음 step으로 전달됩니다.
- Sampling
Y 컬럼의 특정 라벨 기준으로 over sampling 또는 under sampling을 진행 가능합니다. 샘플링 할 라벨을 선택하고, 샘플링할 비율을 입력하는 형식입니다.
- over sampling
- random, smote 방법론을 사용할 수 있습니다.
- argument 사용법은 over_sampling을 확인해주세요
- under sampling
- random, nearmiss 방법론을 사용할 수 있습니다.
- argument 사용법은 under_sampling을 확인해주세요
Train pipeline: Train step
TCR의 Train/Inference step에는 총 5종의 모델이 내장되어 있습니다. 데이터 분석가들이 classification/regression 모델을 만들며 자주 사용한 모델 5종과 각 모델 별 파라미터 세트를 선정하였습니다. TCR의 모델 리스트와 파라미터 세트는 아래와 같습니다
TCR 내장 모델
- rf: random forest
- (max_depth: 6, n_estimators: 300), (max_depth: 6, n_estimators: 500)
- gbm: gradient boosting machine
- (max_depth: 5, n_estimators: 300), (max_depth: 6, n_estimators: 400), (max_depth: 7, n_estimators: 500)
- lgbm: light gradient boosting machine
- (max_depth: 5, n_estimators: 300), (max_depth: 7, n_estimators: 400), (max_depth: 9, n_estimators: 500)
- cb: catoost
- (max_depth: 5, n_estimators: 100), (max_depth: 7, n_estimators: 300), (max_depth: 9, n_estimators: 500)
- xgb: Extreme Gradient Boosting
- (max_depth: 5, n_estimators: 300), (max_depth: 6, n_estimators: 400), (max_depth: 7, n_estimators: 500)
모델 추가 방법
모델 파일 생성 및 추가는 아래와 같은 순서로 작성합니다.
- 위 코드를 복사하여 '모델명.py' 파일을 생성합니다.
- 상단의 모델 import 부분을 수정합니다.
- 모델에서 제공하는 파라미터 값으로 DEFAULT_PARAM을 작성합니다.
- 모델 라이브러리에서 제공하는 파라미터를 확인하고, HPO로 찾고 싶은 파라미터의 탐색 범위를 DEFAULT_PARAM에 작성합니다.
- 각 파라미터는 값 하나 또는 list 형태로 여러 개 작성할 수 있습니다.
- 'tcr_param_mix': 'one_to_one'으로 설정하면 동일한 위치의 list element간 파라미터 쌍을 만듭니다. (위 예제에서 max_depth, min_samples_split 파라미터에 대해 (3,2), (6,3) 두 개 파라미터 세트가 생성됩니다.)
- 'tcr_param_mix': 'all'로 설정하면 각 파라미터의 모든 list element간 조합으로 파라미터 쌍이 생성됩니다. (위 예제에서 max_depth, min_samples_split 파라미터에 대해 (3,2), (6,2), (3,3), (6,3) 네 개 파라미터 세트가 생성됩니다.)
- class TCR_model의 모델 호출 부분을 수정합니다.
- model변수에 import한 모델을 넣습니다.
- 필요한 경우, fit, load, predict 함수를 구현합니다(Scikit-learn 모델을 사용하면 구현할 필요 없습니다.)
- '모델명.py'를 아래 경로에 넣습니다.
- classification 모델일 경우 tcr_modeling/src_tcr/classification_model/ 밑에 '모델명.py'를 놓습니다.
- regression 모델일 경우tcr_modeling/src_tcr/regression_model/ 밑에 '모델명.py'를 놓습니다.
- experimental_plan.yaml의 train function에 model_list argument를 추가하여 alo를 구동합니다.
- model_list argument 값으로 '모델명.py'의 '모델명'을 list에 포함합니다.ex) model_list: [모델명], model_list: [모델명, rf] ('모델명' 모델과 내장된 rf가 동작 됨)
모델 추가 방법
TCR에 내장된 5종의 모델 외 다른 모델을 사용하고 싶다면, 아래 코드를 참고하여 원하는 모델 파일을 생성해주세요. 생성한 모델 파일을 TCR의 모델 파일 경로에 추가하면 새롭게 추가한 모델과 기존 TCR에 내장된 모델의 HPO를 손쉽게 진행할 수 있습니다. 단 Scikit-learn에서 제공하는 모델만 추가하는 것을 권장합니다. 모델 라이브러리는 fit, load, predict함수가 내장되어 있어야 합니다. 아래는 TCR에 내장된 Random forest 모델 파일 코드입니다.
< TCR 기본 모델 중 Random forest 파일 코드(rf.py) >
from sklearn.ensemble import RandomForestClassifier # 모델 파일 import
from .classifier import Classfier
# default parameter를 세팅합니다. 사용하고자 하는 모델의 파라미터 문서를 참고하여 진행합니다.
DEFAULT_PARAM = {
'max_depth': 6,
'n_estimators': [300, 500],
'random_state': 1234,
'n_jobs': 1,
'tcr_param_mix': 'one_to_one',
}
class TCR_model(Classfier):
def __init__(self, model_name, model_type, param_dict):
model = RandomForestClassifier(**param_dict) # import 한 모델 호출
super().__init__(model_name, model_type, model)
아래 코드는 위 rf.py를 참고하여 Scikit-learn의 decision tree 모델 파일을 생성한 예시입니다.
<Decision Tree 모델 파일 생성(dt.py)>
from sklearn.tree import DecisionTreeClassifier # (1) 모델 import
from .classifier import Classfier
DEFAULT_PARAM = { # (2) DecisionTreeClassifier에서 제공하는 파라미터로 DEFAULT_PARAM 수정
'max_depth': [3,6],
'min_samples_split': [2,3],
'tcr_param_mix': 'one_to_one'
}
class TCR_model(Classfier):
def __init__(self, model_name, model_type, param_dict):
model = DecisionTreeClassifier(**param_dict) # (3) 모델 호출 부분 수정
super().__init__(model_name, model_type, model)
모델 파일 생성 및 추가는 아래와 같은 순서로 작성합니다.
- 위 코드를 복사하여 '모델명.py' 파일을 생성합니다.
- 상단의 모델 import 부분을 수정합니다.
- 모델에서 제공하는 파라미터 값으로 DEFAULT_PARAM을 작성합니다.
- 모델 라이브러리에서 제공하는 파라미터를 확인하고, HPO로 찾고 싶은 파라미터의 탐색 범위를 DEFAULT_PARAM에 작성합니다.
- 각 파라미터는 값 하나 또는 list 형태로 여러 개 작성할 수 있습니다.
- 'tcr_param_mix': 'one_to_one'으로 설정하면 동일한 위치의 list element간 파라미터 쌍을 만듭니다. (위 예제에서 max_depth, min_samples_split 파라미터에 대해 (3,2), (6,3) 두 개 파라미터 세트가 생성됩니다.)
- 'tcr_param_mix': 'all'로 설정하면 각 파라미터의 모든 list element간 조합으로 파라미터 쌍이 생성됩니다. (위 예제에서 max_depth, min_samples_split 파라미터에 대해 (3,2), (6,2), (3,3), (6,3) 네 개 파라미터 세트가 생성됩니다.)
- class TCR_model의 모델 호출 부분을 수정합니다.
- model변수에 import한 모델을 넣습니다.
- 필요한 경우, fit, load, predict 함수를 구현합니다(Scikit-learn 모델을 사용하면 구현할 필요 없습니다.)
- '모델명.py'를 아래 경로에 넣습니다.
- 먼저 TCR의 코드에 접근하기 위해서는 TCR을 1회 구동하여 합니다.
- classification 모델일 경우 ./tcr_modeling/src_tcr/classification_model/ 밑에 '모델명.py'를 놓습니다.
- regression 모델일 경우 ./tcr_modeling/src_tcr/regression_model/ 밑에 '모델명.py'를 놓습니다.
- experimental_plan.yaml의 train step argument를 추가하여 alo를 구동합니다.
- model_list argument 값으로 '모델명.py'의 '모델명'을 list에 포함합니다.ex) model_list: [모델명], model_list: [모델명, rf] ('모델명' 모델과 내장된 rf가 동작 됨)
HPO 기능
TCR의 HPO 진행 방식은 아래와 같습니다.
- HPO를 위한 데이터 분할
- cross-validation 혹은 랜덤하게 샘플링하여 train/validation set을 구분합니다. default는 5 fold cross-validation이 적용되며 설정은 data_split argument로 할 수 있습니다.
- 평가 metric을 기준으로 후보 모델 성능 비교
- 평가 metric의 default 룰은 classification시 accuracy, regression시에는 mse가 적용됩니다. 사용자는 평가 metric을 evaluation_metric argument를 통해 지정할 수 있습니다.
- 평가 metric에 가중치를 주기 위한 강조 라벨을 선택할 수 있습니다. 이는 readiness steplabel](./parameter#target_label) argument 입니다. 과제 마다 y 컬럼의 특정 class에 중점을 두고 모델을 평가해야 하는 상황이 있습니다. 예를 들어, NG 데이터를 잘 맞추는 것이 중요할 경우, target_label을 NG로 설정하고, evaluation_metric을 recall로 설정하면 TCR의 모델 중 NG class의 recall값이 가장 높은 모델과 모델 parameter가 best model & parameter로 선정됩니다.
- 만약, HPO과정에서 evaluation_metric 값이 같은 모델이 여러개 등장하면, 다음과 같은 우선순위로 모델 우선순위를 정하게 됩니다.
- evaluation_metric 값이 동일할 떄:
- classificaiton의 경우 accuracy, f1, recall, precision 순으로 evaluation_metric을 제외한 나머지 metric을 모델별로 비교합니다. (accuracy를 선택하면, f1, recall, precision 순으로 값 비교)
- regression의 경우 r2, mse, mae, rmse 순으로 evaluation_metric을 제외한 나머지 metric을 모델별로 비교합니다.
- 모든 평가 지표 값이 동일할 때:
- 모델의 사이즈가 작을 수록, 모델 사이즈가 유사할 때는 rf, lgbm, gbm, xgb, cb 모델 순으로 선택합니다.
- 단 모든 평가 지표 값이 동일할 때, 사용자가 모델을 직접 추가한 경우 사용자가 추가한 모델이 가장 우선순위가 높습니다.
- 선정된 모델과 모델의 parameter setting으로 전체 학습 데이터 재학습
- HPO시 모델은 전체 학습 데이터 중 일부를 학습하는데 사용하지 않습니다(validation set). 따라서 best모델이 선정된 후 전체 데이터로 모델을 학습하는 과정이 필요합니다.
TCR의 user argument 수정/추가 만으로 사용자는 다양한 HPO 모델링 실험을 할 수 있도록 합니다. 모델링 관련 user arguments는 아래와 같으며 링크로 이동하면 상세 설명을 볼 수 있습니다.
- evaluation_metric
- HPO시 사용할 평가 metric을 지정합니다.
- model_list
- 일부 모델만 선택하여 HPO를 진행할 수 있습니다.
- data_split
- HPO시 데이터 split 방법론을 지정할 수 있습니다.
- hpo_settings
- 각 모델의 parameter set을 지정할 수 있습니다.
XAI 기능 제공
TCR은 각 데이터의 특정 변수가 y값에 어떠한 영향을 미치고 있는지 확인할 수 있는 shapley value 계산 기능을 제공하고 있습니다. shapley_value argument를 True로 변경하면, TCR의 분석 산출물인 output.csv에 각 학습 컬럼 별 데이터 마다 shapley value 값을 확인할 수 있습니다.
Inference pipeline: Input step
Train pipeline과 동일하게 동작하며 Inference pipeline에서는 inference 항목의 dataset_uri 경로의 데이터를 불러옵니다.
inference:
dataset_uri: inference_dataset/
Inference pipeline: Readiness step
검사 목록
- inference 시 categorical 데이터 검사
학습에 사용되는 x 컬럼 중 categorical 컬럼의 경우, preprocess step에서 categorical encoding이 적용됩니다. inference 시 categorical 컬럼에 train에서 사용되지 않은 값이 들어올 경우 인코딩이 불가 하여 학습이 되지 않습니다. 따라서 readiness step에서는 categorical 컬럼의 경우 inference 시 새로운 값이 들어오는지 검사를 하고 있습니다.
Readiness step의 default 로직은 inference 때 새로운 값이 들어오면 에러를 발생시켜 pipeline을 종료합니다. 이는 inference 때 학습에 쓰이지 않은 새로운 카테고리 값이 들어왔기 때문에 사용자에게 이를 알리고, re-train을 권장하기 위함입니다.
이 default 설정 또한 yaml 파일에 user argument인 ignore_new_category를 추가하여 로직을 수정할 수 있습니다.
yaml 파일에 'ignore_new_category: True'를 추가하면, 학습에 사용하지 않은 카테고리 데이터가 들어와도 이를 결측처리하고 infernece 결과를 출력합니다.
- inference 시 새 groupkey값 검사(groupkey 기능 사용시 동작) 학습에 사용한 groupkey값이 아닌 새로운 groupkey 값이 들어올 경우 새로운 groupkey 기준으로 학습한 모델이 없기 때문에 해당 groupkey는 추론을 할 수 없습니다. 따라서 새 groupkey 값은 추론 대상에서 제외됩니다.
Inference pipeline: Preprocess step
Train pipeline의 preprocess step에서 생성한 scikit-learn 기반의 전처리 모델을 로드하여 inference 데이터에 대해 전처리를 적용합니다.
Inference pipeline: Inference step
Inference step에서는 train step에서 학습한 모델을 불러와 inference 데이터 셋을 추론합니다.
TCR Version: 3.0.0