Attention-Based Image-Guided Detection for Domain-Specific Object Recognition

Introduction: Practical Implementation of Image-Guided Detection
In the field of Open-Vocabulary Detection, OWL-v2 (Open-World Localization Vision Transformer v2) is a powerful model that can use both text and images as prompts. Particularly, Image-Guided Detection using "Visual Prompting" is a powerful feature that allows users to find desired objects with just example images.
This post shares 3 core optimization techniques that we applied while implementing OWL-v2's Image-Guided Detection methodology to fit production environments.
1. 🚀 OWL-v2: What is Image-Guided Detection?
Traditional Object Detectors can only find pre-trained classes like 'dog' or 'cat'. However, OWL-v2 can find even previously unseen objects when given 'text' or 'image' prompts.
- Text-Guided: "red hat" (text) → Detect red hats in images
- Image-Guided: ⛑️(hat photo) (image) → Detect objects 'similar' to that hat in images
What we focused on is this Image-Guided approach. When users register an example image saying "find this for me" (One-Shot), the model finds those objects.
However, the basic examples publicly available on Hugging Face have several limitations for real service applications:
- "Which" embedding to use as query? Selecting one most 'object-like (Objectness)' embedding from the example image (One-Shot) may not always be the optimal representative value (query).
- Can we utilize K-Shot? If there are 5 example images (Shots), the basic approach cannot effectively "fuse" this information to create a better query.
We implemented the following optimization techniques to overcome these limitations.
2. 💡 Core Optimization Methodologies
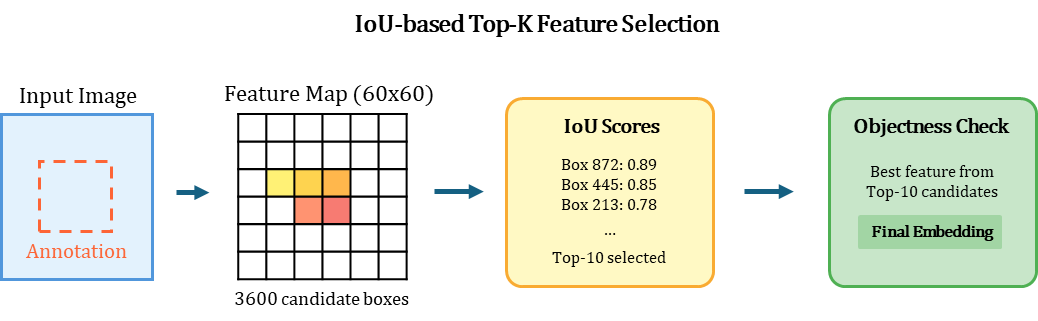
2.1. Smart Box-to-Feature Alignment (Combination of IoU and Objectness)
The most important first step is extracting the best 'query embedding' from the exemplar image.
While typical implementations simply crop and process the bounding box region, this causes resolution issues and context loss. We implemented IoU Matching at the Feature Map level.
Why is this method better?
- Enables robust feature extraction even with inaccurate annotation boxes.
- Unlike simple cropping, it utilizes the entire context of the Feature Map.
- Corrects position with IoU and ensures quality with Objectness Score.
2.2. Class-wise Averaging (Meta-Learning for K-Shot)
If multiple examples (K-Shot) are registered for the same class, how should we utilize them? We borrowed the idea from Meta-Learning's Prototypical Networks and use the 'mean' of embeddings from the same class.
This simple technique reduces noise and bias from One-Shot and generates a much more stable 'Prototype' query representing the class.
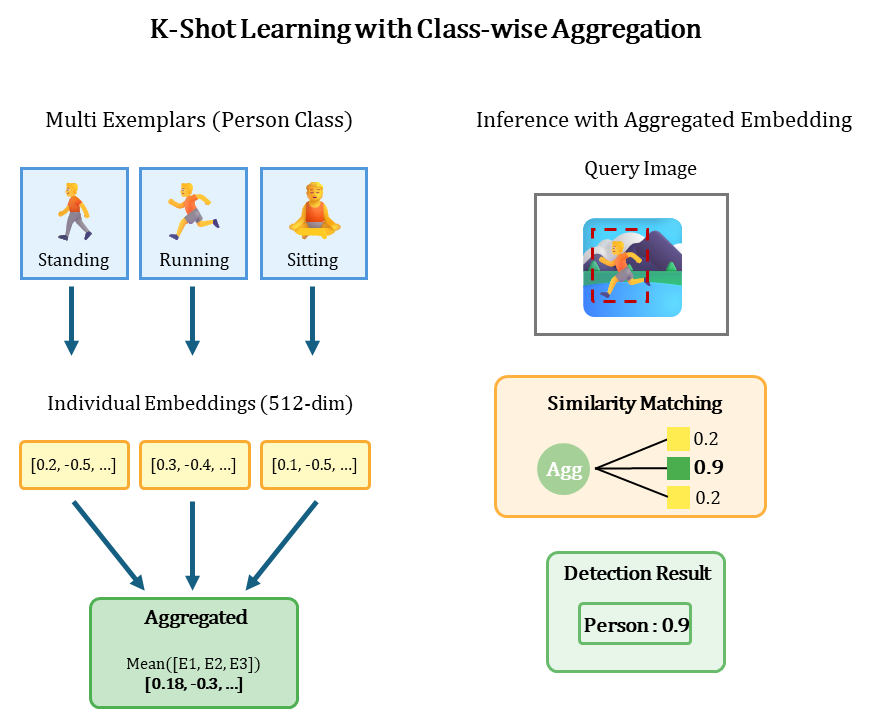
Note: The optimal number of shots is 3-5, and performance does not improve with more shots beyond this.
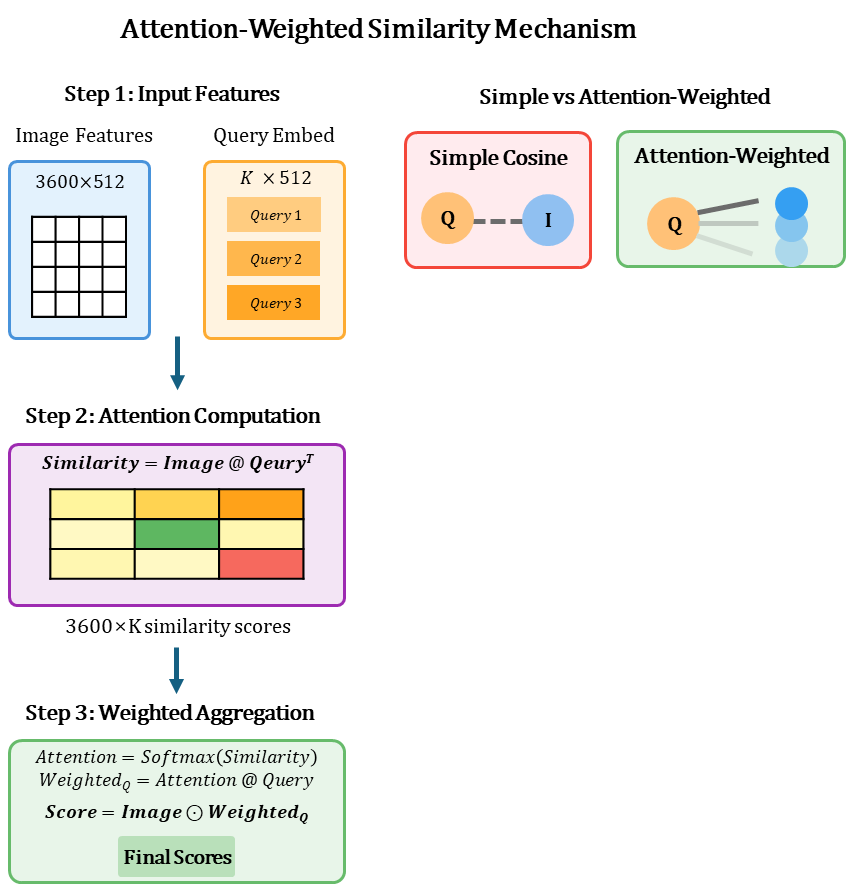
2.3. Context-Aware Matching (Attention-Weighted Similarity)
Now it's time to compare the query embedding (Exemplar) with the target image embedding (Image Feature).
While standard implementations use simple cosine similarity, we introduced an Attention mechanism to calculate "context-aware" similarity (Context-Aware Matching).
Advantages of this approach:
- Multi-Exemplar Fusion: Naturally fuses information from multiple examples (K-Shot).
- Contextual Weighting: Automatically learns the importance of each spatial location in the target image based on the query.
- Noise Suppression: Minimizes the influence of unrelated background regions.
3. 📈 Key Insights and Performance Benchmarks
3.1. Key Insights Discovered
- Feature-level Matching > Pixel-level Cropping: IoU-based feature selection showed approximately 3-5%p improvement in mAP compared to simple cropping.
- Attention Weighting Effect: Particularly in cluttered backgrounds, False Positives decreased by approximately 15%.
3.2. Performance Benchmarks
Results measured in actual industrial environments (based on A100 GPU):
- Processing Speed:
- Feature Extraction: ~50ms / image
- Inference (10 targets): ~30ms / image
- End-to-End Latency: < 100ms
- Accuracy (Custom Industrial Dataset):
- Generic Objects: mAP 0.72
- Specific Poses: mAP 0.45
4. 🏛️ Production Architecture: Separation of 'Registration' and 'Inference'
To efficiently serve all these optimization techniques, we designed an architecture that separates model serving into "two independent APIs".
-
Object Registration (get_embedding):
- Users provide example images and bounding boxes.
- The server extracts the 'Query Embedding' that best represents this object through the Smart Box-to-Feature Alignment logic in
2.1. - The extracted embedding is stored in the Embedding Store (Vector DB, etc.) along with the class name.
-
Object Detection (inference):
- Users request object names (
targets) they want to find and target images. - The server loads the embedding(s) of those
targetsfrom the Embedding Store. - Performs
2.2(Averaging),2.3(Attention), and calibration logic sequentially to return final detection results.
- Users request object names (
This structure, as a core pattern of MLOps, provides the following substantial benefits:
- Embedding Reuse: Once extracted, exemplar embeddings can be rapidly reused across thousands or tens of thousands of images.
- Dynamic Target Selection: Flexibly select and combine targets to detect at inference time.
- Memory Efficiency: While the model itself resides in GPU, memory usage is highly efficient as only the necessary target embeddings (simple vectors) are loaded.
5. Conclusion
While applying OWL-v2's Image-Guided Detection to production environments, we achieved practical performance through various optimization techniques. Particularly, Attention-Weighted Similarity and IoU-based Feature Selection showed significant performance improvements over existing implementations.
However, limitations still exist in situations with complex poses or extreme domain shifts.

