Attention-Based Image-Guided Detection for Domain-Specific Object Recognition

서론: Image-Guided Detection의 실용적 구현
Open-Vocabulary Detection 분야에서 OWL-v2 (Open-World Localization Vision Transformer v2)는 텍스트와 이미지 모두를 프롬프트로 사용할 수 있는 강력한 모델입니다. 특히 "이미지 프롬프트(Visual Prompting)"를 이용한 Image-Guided Detection은, 사용자가 예시 이미지만으로 원하는 객체를 찾게 해주는 강력한 기능입니다.
본 포스트에서는 OWL-v2의 Image-Guided Detection 방법론을 Production 환경에 맞게 구현하며 적용한 핵심 최적화 기법 3가지를 공유합니다.
1. 🚀 OWL-v2: Image-Guided Detection이란?
일반적인 Object Detector는 '개', '고양이'처럼 미리 학습된 클래스만 찾을 수 있습니다. 하지만 OWL-v2는 '텍스트'나 '이미지'를 프롬프트로 주면, 처음 보는 객체도 찾아냅니다.
- Text-Guided: "빨간색 모자" (텍스트) -> 이미지에서 빨간색 모자 탐지
- Image-Guided: ⛑️(모자 사진) (이미지) -> 이미지에서 해당 모자와 '유사한' 객체 탐지
저희가 집중한 것은 바로 이 Image-Guided 방식입니다. 사용자가 "이것 좀 찾아줘"라고 예시 이미지를 등록하면(One-Shot), 모델이 해당 객체를 찾아내는 기능이죠.
하지만 Hugging Face 등에 공개된 기본 예제는 �실제 서비스에 적용하기에 몇 가지 한계가 있습니다.
- "어떤" 임베딩을 쿼리로 쓸 것인가? 예시 이미지(One-Shot)에서 가장 '객체다운(Objectness)' 임베딩 하나를 고르는데, 이게 항상 최적의 대표 값(쿼리)이 아닐 수 있습니다.
- K-Shot을 활용할 수 있는가? 만약 예시(Shot)가 5장이라면, 기본 방식은 이 5장의 정보를 효과적으로 "융합"하여 더 나은 쿼리를 만들지 못합니다.
저희는 이러한 한계를 극복하기 위해 다음과 같은 최적화 기법들을 구현했습니다.
2. 💡 핵심 최적화 방법론
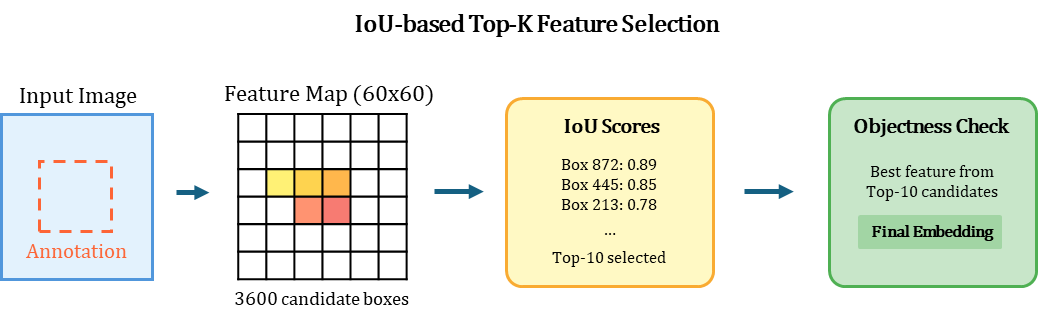
2.1. Smart Box-to-Feature Alignment (IoU와 Objectness의 결합)
가장 중요한 첫 단계는 예시 이미지(Exemplar)에서 가장 좋은 '쿼리 임베딩'을 추출하는 것입니다.
일반적인 구현은 단순히 Bounding Box 영역을 Crop하여 처리하지만, 이는 해상도 문제와 컨텍스트 손실을 야기합니다. 저희는 Feature Map 레벨에서 IoU Matching을 구현했습니다.
왜 이 방법이 더 나은가?
- Annotation Box가 부정확해도 Robust한 특징 추출이 가능합�니다.
- 단순 Crop과 달리 Feature Map의 전체 컨텍스트를 활용합니다.
- IoU로 위치를 보정하고, Objectness Score로 품질을 보장합니다.
2.2. Class-wise Averaging (K-Shot을 위한 Meta-Learning)
만약 동일한 클래스에 대해 여러 장의 예시(K-Shot)가 등록되었다면, 이를 어떻게 활용해야 할까요? 저희는 Meta-Learning의 Prototypical Network 아이디어를 차용, 동일 클래스의 임베딩을 '평균(mean)' 내어 사용합니다.
이 간단한 기법은 One-Shot의 노이즈나 편향을 줄여주고, 클래스를 대표하는 훨씬 더 안정적인 '프로토타입(Prototype)' 쿼리를 생성합니다.
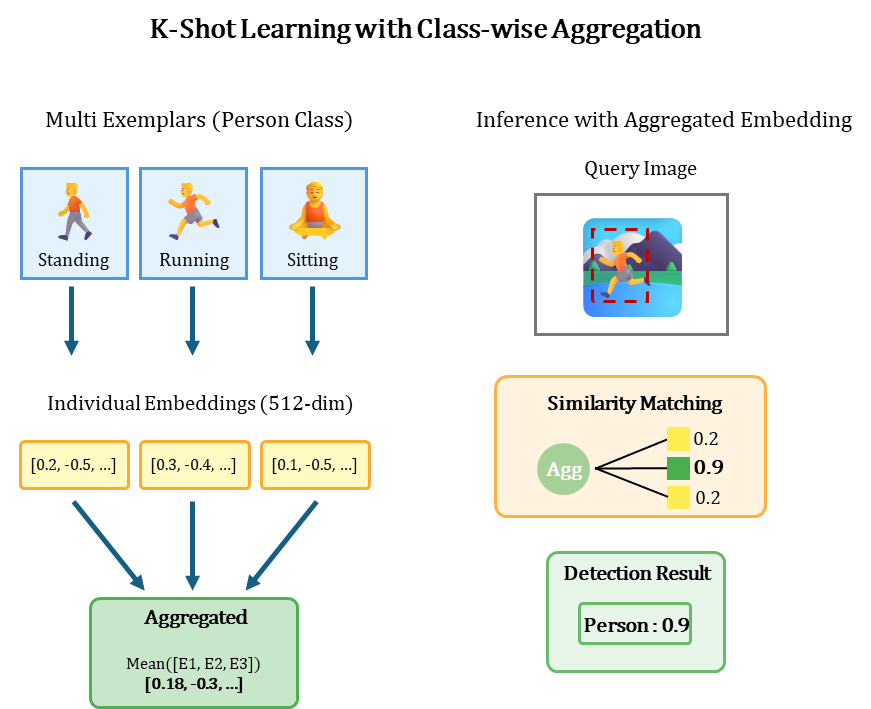
단, Optimal Shot의 수는 3~5이며, 그 이상 많은 Shot일 수록 성능이 좋아지지는 않음.
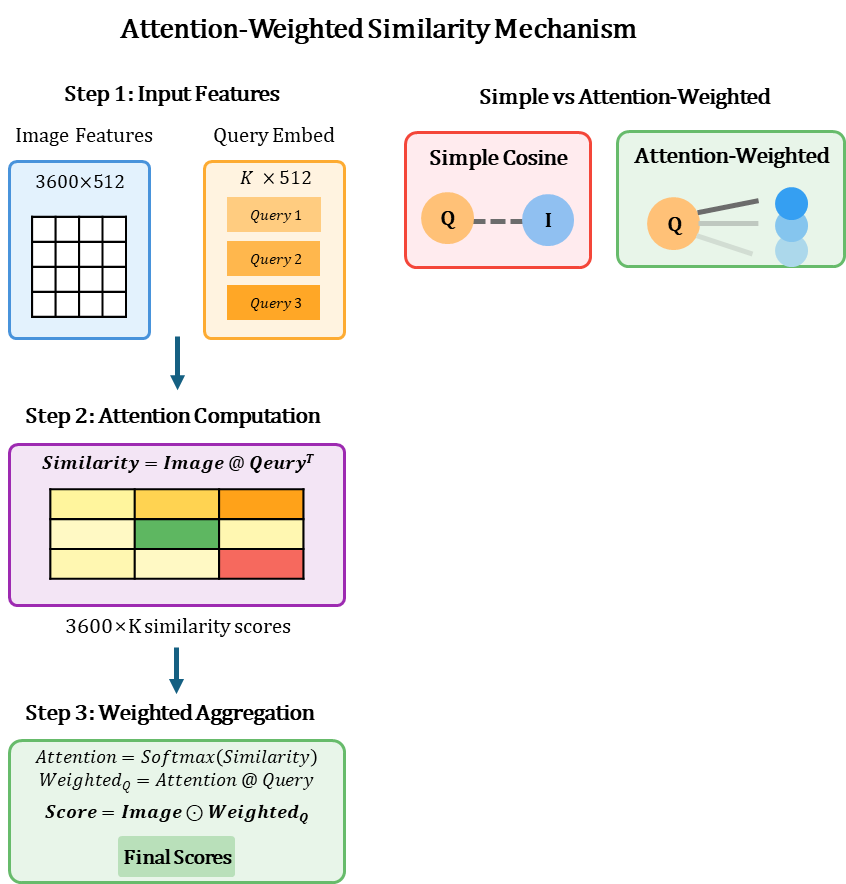
2.3. Context-Aware Matching (Attention-Weighted Similarity)
이제 쿼리 임베딩(Exemplar)과 타겟 이미지의 임베딩(Image Feature)을 비교할 차례입니다.
표준 구현은 단순 코사인 유사도를 사용하지만, 저희는 Attention 메커니즘을 도입하여 "문맥을 고려한" 유사도(Context-Aware Matching)를 계산합니다.
이 방식의 장점:
- Multi-Exemplar Fusion: 여러 예시(K-Shot)의 정보를 자연스럽게 융합합니다.
- Contextual Weighting: 타겟 이미지의 각 공간적 위치(Spatial Location)의 중요도를 쿼리에 따라 자동으로 학습합니다.
- Noise Suppression: 관련 없는 배경 영역의 영향을 최소화합니다.
3. 📈 주요 인사이트 및 성능 벤치마크
3.1. 발견한 주요 인사이트
- Feature-level Matching > Pixel-level Cropping: IoU 기반 Feature 선택은 단순 Crop 방식 대비 mAP가 약 3~5%p 향상되었습니다.
- Attention Weighting 효과: 특히 복잡한 배경(Cluttered Background)에서 False Positive(오탐)가 약 15% 감소했습니다.
3.2. 성능 벤치마크
실제 산업 환경(A100 GPU 기준)에서의 측정 결과입니다.
- 처리 속도:
- Feature Extraction: ~50ms / image
- Inference (10 targets): ~30ms / image
- End-to-End Latency: < 100ms
- 정확도 (Custom Industrial Dataset):
- 일반 객체 (Generic Objects): mAP 0.72
- 특정 자세 (Specific Poses): mAP 0.45
4. 🏛️ 실전 아키텍처: '등록'과 '추론'의 분리
이 모든 최적화 기법을 효율적으로 서빙하기 위해, 저희는 모델 서빙을 "두 개의 독립된 API" 로 분리하는 아키텍처를 설계했습니다.
-
객체 등록 (get_embedding):
- 사용자가 예시 이미지와 Bounding Box를 제공합니다.
- 서버는
2.1의 Smart Box-to-Feature Alignment 로직을 통해 이 객체를 가장 잘 나타내는 '쿼리 임베딩(Query Embedding)'을 추출합니다. - 추출된 임베딩은 클래스 이름과 함께 Embedding Store (Vector DB 등) 에 저장됩니다.
-
객체 탐지 (inference):
- 사용자가 찾고 싶은 �객체 이름(
targets)과 타겟 이미지를 요청합니다. - 서버는 Embedding Store에서 해당
targets의 임베딩(들)을 불러옵니다. 2.2(Averaging),2.3(Attention),2.4(Calibration) 로직을 순차적으로 수행하여 최종 탐지 결과를 반환합니다.
- 사용자가 찾고 싶은 �객체 이름(
이 구조는 MLOps의 핵심 패턴으로서 다음과 같은 막대한 이점을 제공합니다.
- Embedding 재사용: 한 번 추출한 exemplar 임베딩을 수천, 수만 장의 이미지에 고속으로 재사용할 수 있습니다.
- 동적 타겟 선택: Inference 시점에 검출할 타겟을 유연하게 선택하고 조합할 수 있습니다.
- 메모리 효율성: 모델 자체는 GPU에 상주하되, 필요한 타겟의 임베딩(단순 벡터)만 로드하므로 메모리 사용량이 매우 효율적입니다.
5. 결론
OWL-v2의 Image-Guided Detection을 Production 환경에 적용하며, 저희는 여러 최적화 기법을 통해 실용적인 성능을 달성했습니다. 특히 Attention-Weighted Similarity와 IoU-based Feature Selection은 기존 구현 대비 의미 있는 성능 개선을 보였습니다.
그러나 복잡한 자세(Complex Pose)나 극단적인 도메인 변화(Extreme Domain Shift) 상황에서는 여전히 한계가 존재합니다.

