From One-Shot Decisions to Two-Stage Reasoning



한 번에 모든 것을 판단하기보다, 단계 별로 신중하게
AI가 카메라 화면 한 장을 보고 판단을 내리는 과정은 생각보다 복잡합니다. 사용자는 자연스럽게 “사람이 쓰러지면 알려주세요”, “마스크를 쓰지 않은 작업자를 알려주세요”처럼 간단한 요청을 하지만, AI는 이 요청을 처리하기 위해 사진 분석, 조건 충족 여부 판단, 예외 상황 고려, 최종 결정, 이유 설명까지 여러 과정을 단 한 번에 수행해야 합니다.
EVA에서는 이를 해결하기 위해 사용자의 요청을 탐지 조건(Detection) 과 예외 조건(Exception) 으로 구조화하는 Enriched Input 방식을 도입했고 성능이 크게 좋아졌습니다. 하지만 입력을 구조화 했음에도 불구하고, 여러 요청을 처리하는 과정에서 AI가 여전히 모순된 판단을 내리는 경우가 있었습니다.
즉, 문제는 단순히 조건을 구조화 하는 것 뿐만 아니라, AI가 여러 판단을 한 번에 수행해야 한다는 방식 자체에 있었던 것입니다. 그래서 EVA는 기존의 One-Shot 방식이 가진 한계를 넘어, 두 단계로 나누어 판단하는 Two-Stage Reasoning 구조를 새롭게 도입했습니다.
본 포스트에서는
- 구조화만으로 해결되지 않았던 문제
- One-Shot 판단이 가진 근본적 한계
- 두 단계로 판단을 나누었을 때 AI가 더 잘 작동하는 이유
- 실제 실험으로 확인한 개선 효과
를 중심으로 Two-Stage 구조의 도입 과정을 소개합니다.
1. 구조화된 요청만으로 해결되지 않는 문제들
EVA는 사용자의 자연어 Input을 구조화 된 Enriched Input으로 자동으로 바꿔주는 기능을 활용하여 “미착용 탐지”, “쓰러짐 탐지” 등 대부분의 간단한 요청에서 성능을 눈에 띄게 개선했습니다. 그러나, 여전히 이해할 수 없는 VLM(Vision Language Model) 판단 결과는 종종 발생합니다.
예시 사례
Detection Steps
- 영상 내 사람이 존재함 → True
- 최소 1명 이상이 쓰러져 있음 → True
Exceptions
- 쓰러진 사람의 몸을 확인하기 어려움(몸 가려짐 등) → True
- 쓰러진 사람의 형체를 확인하기 어려움(사람의 실루엣만 보이거나, 신발과 같은 사람의 일부(사람 신체의 50%미만)만 보이는 경우 등) → False
- 쓰러진 사람이 위험하지 않은 경우(핸드폰을 보고 있거나, 책상 위에 누워 있는 상태 등) → True
- 이미지의 화질로 인해 정확한 판단이 어려운 경우 → False
AI 판단 탐지 결과: False Evidence: 사람이 쓰러진 것으로 보이지만 위험한 상황으로 판단하긴 어렵습니다
위와 같이 탐지 조건과 예외 조건을 명확히 나누어줬음에도 Detection 결과, Exception 그리고 Evidence가 서로 모순되는 상황이 발생했고, 한 번의 Inference에 여러 판단을 시키는 방식 자체가 문제가 있을 수 있다는 가능성을 시사합니다.
2. One-Shot 판단의 근본적 한계
EVA에서 AI가 동시에 수행하는 일은 다음과 같습니다.
- 이미지 분석
- 탐지 조건 충족 여부 판단
- 예외 여부 확인
- 최종 결정
- 설명 생성
이 구조에서 모델이 최종 결정을 내리는 시점에 발생하는 판단 오류는 다음과 같이 3가지입니다.
(1) 탐지 조건과 이유만 보고 결론 도출 (2) 예외 여부만 보고 결론 도출 (3) 둘을 적절히 통합하지 못해 서로 모순되는 결론과 근거가 함께 출력
탐지 조건과 예외 처리가 많아질수록 VLM 모델이 탐지, 예외 확인, 결론, 설명을 일관성 있게 동시에 수행�하기는 어렵습니다. 특히 경량 모델의 경우엔 그 수행 능력이 현저히 떨어지는 것도 관찰할 수 있었습니다.
3. Two-Stage Reasoning 도입
Google Brain의 논문 "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (wei et al. 2022)" 에서는 LLM이 복잡한 문제를 해결할 때, 정답을 한 번에 요구하는 것보다 "중간 사고 과정(step-by-step reasoning)"을 분리해 주었을 때 성능이 크게 향상된다고 합니다. "복잡한 판단을 여러 단계로 쪼개면 모델이 더 안정적으로 추론한다"는 핵심 아이디어가 VLM 판단 구조와도 동일하게 적용될 수 있다고 보였습니다.
EVA의 Two-Stage Reasoing
“한 번에 모든 것을 시키지 말고, 작은 판단을 순서대로 시키자.”
-
1단계 – Detection (탐지): "의심스러운 상황인가?"
- 목표: 놓치지 않는 것
- 예외는 고려하지 않음
-
2단계 – Exception (예외 확인): "일반적인 상황인가?"
- 목표: 오탐 줄이기
- 오류가 발생할 수 있는 특수한 상황에 집중
- 예외 조건에 해당하면 알람을 보내지 않음
이미지 → [Detection VLM] → (조건 불충족) → 정상 종료
└→ (조건 충족) → [Exception VLM] → (예외 True) → 알람 X
└→ (예외 False) → 탐지 알람
즉, EVA의 Two-Stage Reasoning은 텍스트 LLM의 Chain-of-Thought 기법을 감시 솔루션에 맞게 구조적 규칙으로 재해석해 적용한 방식이라고 할 수 있습니다.
사실 사람도 같은 방식으로 일을 처리합니다. 한 번에 여러 판단을 하려 하면 실수하기 쉽지만, 단계별로 하나씩 판단하면 훨씬 정확해집니다. 위 구조를 적용하여 VLM은 한 번에 여러 일을 처리하는 대신, 각 단계에서 하나의 목표에만 집중할 수 있게 되었습니다.
4. Detection Step & Exceptions
Two-Stage Reasoning을 반영한 구조는 아래 그림과 같습니다.
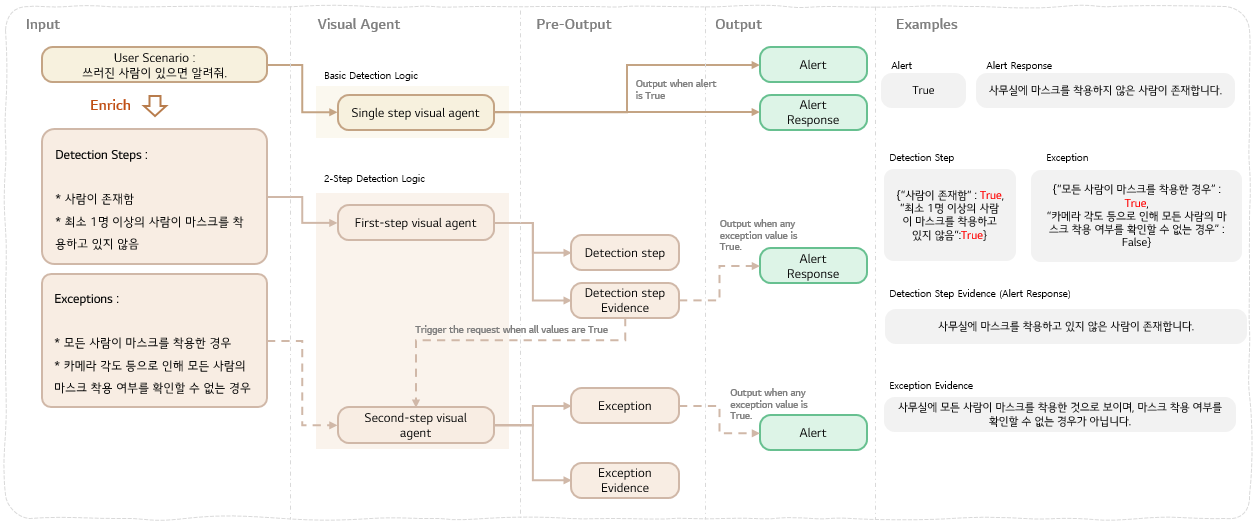
4.1 의심스러운 상황을 Step-By-Step으로 포착하는 Detection 단계
1단계는 핵심 목표가 분명합니다.
"놓치지 않는 것" 즉, 최대한 넓은 그물로 의심스러운 상황을 포착하는 것입니다.
원칙은 다음과 같습니다.
- 앞의 조건부터 순차적으로 탐지
- 예외 상황은 고려하지 않음
- 오탐이 발생해도 좋음 (다음 Stage에서 정밀하게 걸러낼 것이기 때문)
예시 질문: 마스크 미착용 탐지
- 사진에 사람이 있는가?
- 최소 1명 이상이 마스크를 착용하지 않은 것처럼 보이는가?
이 단계는 말 그대로 최대한 넓게 탐지하는 단계입니다.
4.2 정상 상황을 정확히 배제하는 Exception 단계
Exception Stage의 목표는 Detection과 정반대입니다.
"오탐을 줄이는 것" 탐지 단계를 통과한 상황이라도 정상일 수 있으므로 이를 철저히 걸러내는 단계입니다.
여기에서 EVA는 중요한 원칙 하나를 도입했습니다.
"예외 조건은 전체 기준으로만 정의한다."
즉, 사람별/부분별로 애매하게 나누지 않고 "전체가 정상인지"만 확인하는 것입니다.
- 모든 사람이 마스크를 착용했는가?
- 얼굴이 가려지거나 화질 저하로 판단이 어려운가?
둘 중 하나라도 True라면 → 정상(알람 없음) 둘 다 False라면 → 실제 문제(알람 발송)
5. Two-Stage Reasoning의 장점
Two-Stage 방식은 단순히 “단계를 둘로 나눈 것”이 아닙니다.
5-1. 역할 분리 → 혼란 감소
- 1단계는 재현율(Recall) 중심
- 2단계는 정밀도(Precision) 중심
서로 다른 목적을 한 번에 충족할 필요가 없으니 AI가 훨씬 안정적으로 판단합니다.
5-2. 기준을 나누면 판단의 명확성이 높아짐
- 1단계는 “의심 여부”
- 2단계는 “정상 여부”
각 단계의 기준이 분명하기 때문에 AI의 판단도 더 명확해집니다.
5-3. 확증 편향 방지
최초엔 Detection Stage에서의 판단을 Exceptsion Stage에 넘겨주어 최종 결론을 도출하는 방식을 선택했습니다. EVA는 탐지 솔루션이기 때문에 Detection Stage에 가중치를 주기 위함이었습니다.
하지만 실험 결과는 반대였습니다. 탐지 결과를 넘겨주면 Exception Stage에서 그 결론을 그대로 따라가며 예외 판단을 제대로 수행하지 못했습니다.
그래서 결국 이미지만 보고 완전히 독립적으로 판단하도록 설계했고, 더 나은 결과를 확인할 수 있었습니다.
6. 성능 평가 결과
다음은 시나리오 별 Two-Stage Reasoning을 적용하여 성능을 평가한 결과입니다.
6.1 쓰러짐 탐지: 영상 내 쓰러진 사람이 있는지 판별하는 Test
| 구성 | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.99 | 0.87 | 0.97 |
| Two-Stage Reasoning | 0.99 | 0.99 | 0.91 |
2-step 적용 시, precision이 0.87 → 0.99로 크게 향상되어 오탐(false positive)을 크게 줄일 수 있습니다.
6.2 마스크 미착용 탐지: 작업 공간 내 마스크 미착용자 검출 Test
| 구성 | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.59 | 0.73 | 0.52 |
| Two-Stage Reasoning | 0.61 | 0.70 | 0.63 |
모든 사람의 마스크 착용 여부를 확인해야 하는 어려운 Task이지만 Detection Step을 제공하여 탐지율을 향상 시켰습니다.
6.3 기타(방화, 버스 탐지 등)
| 구성 | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.60 | 0.63 | 0.53 |
| Two-Stage Reasoning | 0.61 | 0.70 | 0.63 |
같은 모델, 같은 영상, 같은 시나리오에서 판단 구조만 바꾼 결과는 놀라웠습니다.
상대적으로 난이도가 높다고 판단되는
- 그림자로 인한 착시
- 날씨에 의한 화질 저하
- 복잡한 작업 공간 등의 케이스들에 대해서도 오탐률이 대폭 감소하거나 탐지 성능이 향상되는 것을 확인할 수 있었습니다.
Two-Stage Reasoning은 AI가 더 정확하고, 더 논리적이고, 더 신뢰할 수 있는 판단을 수행할 수 있는 발판이 되었습니다.
결론
Two-Stage Reasoning을 적용해보면서
중요한 건 "어떤 모델을 쓰느냐"보단 "얼마나 명확하게 지시해주느냐"라는 것을 알 수 있었습니다.
한 번에 모든 것을 시키면 AI는 쉽게 혼란스러워지고 모순된 판단을 하게 됩니다.
그러나 판단을 단계별로 분리하고 각 단계에서 해야 할 일을 명확히 제시하면, AI는 훨씬 안정적이고 일관성 있는 판단을 수행할 수 있습니다.
Two-Stage 구조는 단순한 기술적 개선이 아니라, EVA가 현장에서 더 신뢰 받는 시스템으로 진화하는 데 중요한 발판이 되었습니다.
참고 자료
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903, 2022 (Paper)
- Language Models Perform Reasoning via Chain of Thought (Google Research)
- Chain-of-thought reasoning supercharges enterprise LLMs (K2View Blog)
- Marcetic, Darijan & Hrkać, Tomislav & Ribaric, S.. (2016). Two-stage cascade model for unconstrained face detection. 1-4. 10.1109/SPLIM.2016.7528404 (ResearchGate)
- LLM 환각(hallucination) 및 단계적 완화 파이프라인에 대한 서베이/연구 (MDPI)

