From One-Shot Decisions to Two-Stage Reasoning



Instead of Making a Single Decision, Be Cautious Step-by-Step
The process of AI making a decision from a single camera image is more complex than most people think. Users may simply ask: “Notify me if someone falls down,” “Alert me when a worker isn’t wearing a mask,” But the AI has to: analyze the image, check the requested conditions, consider exceptions, make the final decision, and explain the reasoning — all in a single pass.
In EVA, we introduced an Enriched Input structure that separates the user’s requirements into Detection conditions and Exception conditions, which significantly improved performance. However, even with structured input, the AI still made contradictory judgments in multi-condition scenarios.
The issue was not only about structuring the conditions — but also about forcing the AI to perform multiple judgments all at once. So EVA moved beyond the limitations of the existing one-shot approach and introduced a new Two-Stage Reasoning process.
In this post, we cover:
- Why structured input alone could not solve the problem
- The fundamental limits of one-shot decision-making
- Why AI works better when decisions are split into two stages
- Performance improvements validated by real experiments
1. Problems That Structured Input Alone Cannot Solve
By converting natural language inputs into structured Enriched Input, EVA achieved noticeable performance improvements for simple tasks such as “mask detection” or “fall detection.” However, confusing Vision Language Model (VLM) behavior still surfaced.
Example Case
Detection Steps
- Person present in the image → True
- At least one person appears to have fallen → True
Exceptions
- Hard to confirm body shape of fallen person (occlusion, etc.) → True
- Unable to confirm human form clearly (only silhouette or less than 50% visible, etc.) → False
- The fallen person seems not in danger (lying on a desk, using phone, etc.) → True
- Hard to make accurate judgment due to low image quality → False
AI Decision Detection result: False Evidence: A person appears to be lying down, but it does not seem dangerous.
Despite clearly provided detection and exception logic, the detection result, exception result, and evidence contradict one another — suggesting that forcing multiple decisions in a single inference pass may be fundamentally flawed.
2. Fundamental Limits of One-Shot Judgment
In EVA, the AI simultaneously performs:
- Image analysis
- Checking detection condition
- Checking exception condition
- Making the final decision
- Generating explanation
The errors occurring at the moment of final decision fall into three categories:
- A conclusion derived only from detection conditions
- A conclusion derived only from exception conditions
- Failure to properly integrate both → contradictory results
As the number of conditions grows, VLMs struggle to deliver consistent results in detection, exception evaluation, conclusion, and explanation all at once. This is more pronounced in lightweight models, where ability is significantly reduced.
3. Introducing Two-Stage Reasoning
Google Brain’s research "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)" demonstrated that LLMs solve complex problems better when the reasoning process is broken into steps instead of requiring an answer immediately. The key idea — “complex reasoning improves when broken down into smaller steps” — fits perfectly for VLM-based judgment.
EVA’s Two-Stage Reasoning
“Don’t ask the model to do everything at once. Ask step-by-step.”
-
Stage 1 – Detection: “Is this a suspicious situation?”
- Goal: Don’t miss anything
- Exceptions not considered
-
Stage 2 – Exception Checking: “Could this be normal?”
- Goal: Reduce false alarms
- Focus only on special cases where mistakes are likely
- If any exception is True → no alert
Image → [Detection VLM] → (Fail) → Normal End
└→ (Pass) → [Exception VLM] → (Exception True) → No Alert
└→ (Exception False) → Trigger Alert
This is essentially applying Chain-of-Thought reasoning as structured rules tailored to a monitoring solution.
Humans do the same — making multiple decisions at once easily leads to mistakes, but judgments become much more accurate when done step-by-step.
With this structure, the VLM focuses on one mission per stage, improving consistency.
4. Detection Step & Exceptions
Below is the structure reflecting Two-Stage Reasoning.
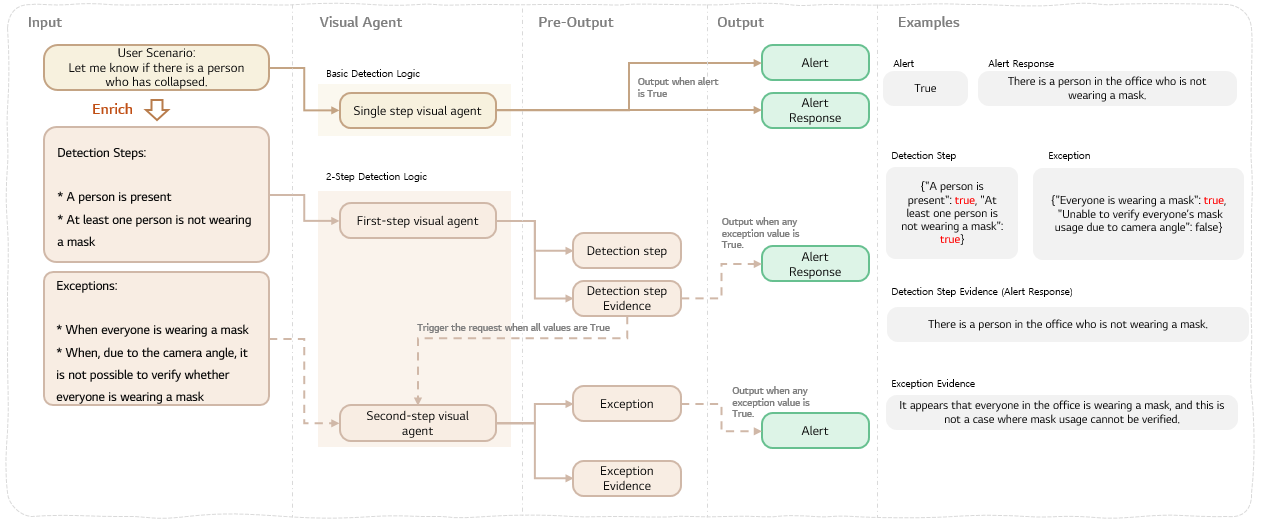
4.1 Detection Stage — Capture Suspicious Cases Step-by-Step
Stage 1 has a clear mission:
“Do not miss anything.”
In other words, cast a wide net to catch suspicious situations.
Principles:
- Evaluate conditions sequentially
- Do not consider exceptions
- False positives are acceptable (They will be filtered later)
Example: Mask Non-Wearing Detection
- Is there any person in the image?
- Does at least one person appear to not be wearing a mask?
This stage is intentionally broad.
4.2 Exception Stage — Filter Out Normal Situations Precisely
The goal here is opposite:
“Reduce false positives.”
Even if suspicious, the situation may still be normal — this stage filters such cases.
A key rule introduced in EVA:
“Exceptions are defined only at the overall level.”
Not per-person or partly ambiguous — check whether the whole situation is normal.
Examples:
- Is every person wearing a mask?
- Is judgment difficult due to occlusion or poor quality?
If either is True → Normal (No alert) If both are False → Real issue (Alert)
5. Advantages of Two-Stage Reasoning
Two-Stage reasoning is not just “adding another step.”
5-1. Role Separation → Less Confusion
- Stage 1 focuses on recall
- Stage 2 focuses on precision
The model no longer needs to satisfy conflicting objectives at once.
5-2. Clearer Judgment Boundaries
- Stage 1 → “Suspicious?��”
- Stage 2 → “Normal?”
Clarity in criteria leads to clarity in reasoning.
5-3. Preventing Confirmation Bias
Initially, EVA passed the Stage 1 outcome into Stage 2 to help detection. But the result was the opposite: Stage 2 blindly followed Stage 1 decisions.
Now, both stages make decisions independently, using only the image — improving results significantly.
6. Performance Evaluation
Here are results applying Two-Stage Reasoning per scenario:
6.1 Fall Detection
| Method | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.99 | 0.87 | 0.97 |
| Two-Stage Reasoning | 0.99 | 0.99 | 0.91 |
Precision improved dramatically 0.87 → 0.99, reducing false positives significantly.
6.2 Mask Non-Wearing Detection
| Method | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.59 | 0.73 | 0.52 |
| Two-Stage Reasoning | 0.61 | 0.70 | 0.63 |
Though a difficult task requiring full mask verification, detection rates improved thanks to Stage 1.
6.3 Others (Arson, Bus, etc.)
| Method | accuracy | precision | recall |
|---|---|---|---|
| One-Shot Decision | 0.60 | 0.63 | 0.53 |
| Two-Stage Reasoning | 0.61 | 0.70 | 0.63 |
Even in challenging cases:
- Visual illusions caused by shadows
- Low image quality
- Complex environments
False positives dropped significantly and detection performance improved.
Two-Stage Reasoning enables AI to make more accurate, logical, and trustworthy judgments.
Conclusion
Through Two-Stage Reasoning, we learned:
What matters is not which model you use, but how clearly you instruct it.
When asked to do everything at once, AI becomes confused and contradictory. But when tasks are divided with a clear role for each stage, AI becomes far more stable and consistent.
This structural improvement plays a crucial role in making EVA a more reliable solution in the field.
References
- J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903, 2022 (Paper)
- Language Models Perform Reasoning via Chain of Thought (Google Research)
- Chain-of-thought reasoning supercharges enterprise LLMs (K2View Blog)
- Marcetic, Darijan & Hrkać, Tomislav & Ribaric, S.. (2016). Two-stage cascade model for unconstrained face detection. 1-4. 10.1109/SPLIM.2016.7528404 (ResearchGate)
- Survey/Research on LLM hallucination and step-by-step mitigation pipelines (MDPI)

