Teaching VLMs to Multitask: Enhancing Situation Awareness through Scenario Decomposition

At the core of EVA lies the ability to truly understand critical situations that occur simultaneously within a single scene—such as fires, people falling, or traffic accidents—without missing any of them. However, no matter how capable a Vision-Language Model (VLM) is, asking it to reason about too many things at once leads to a sharp degradation in cognitive performance.[2,3]
In this post, inspired by the recent text-to-video retrieval research Q₂E (Query-to-Event Decomposition)[1], we introduce Scenario Decomposition, a technique that enables VLMs to deeply understand complex, multi-scenario situations within a single frame.
1. 🚀 The Problem: Cognitive Bottlenecks in VLMs
EVA Agents are required to monitor complex urban roads and multi-use facilities 24/7. In the early stages, we trusted the general-purpose capabilities of VLMs and expected them—like humans—to grasp all situations at once.
[Initial Approach: Unified Query] "Look at this CCTV footage and check whether there is a fire, a fallen person, a traffic accident, or an emergency vehicle entering."
In practice, however, the model revealed the limits of selective perception. For example, it may clearly recognize a large bus in the center of the frame, while treating fire indicators or a fallen person behind it as mere background noise.
This occurs because the model’s attention mechanism is spread across multiple targets, resulting in shallow contextual understanding of critical risk signals.
2. 💡 The Solution: Extending Cognition with Q₂E
To address this issue, we adopted the core philosophy of Q₂E: “Complex events become easier to understand when they are decomposed.”
2.1. Key Insight from Q₂E (Query-to-Event)
The Q₂E paper demonstrates that instead of searching with a single term like “wildfire”, decomposing it into an event flow—precursor → progression → outcome—allows the model to retrieve and understand the event far more effectively.
2.2. EVA Agent Adoption: Scenario Decomposition
We extended this idea into Multi-Scenario Understanding. Rather than asking a VLM to observe everything broadly at once, we assign it distinct perspectives, each focused on a specific scenario.
-
Before (Single Perspective): “Notify me if there is a fire, a fallen person, or a traffic accident.” → (Ambiguous, attention dispersed)
-
After (Decomposed Perspectives):
- [Fire Perspective]: “Focus on pixel changes, colors, and smoke textures to identify signs of fire.”
- [Safety Monitoring Perspective]: “Analyze human pose and interactions with surrounding objects to detect falls.”
- [Traffic Monitoring Perspective]: “Examine vehicle collisions or abnormal stopping behavior to determine accidents.”
By decomposing the query this way, the VLM’s visual encoder activates strong, scenario-specific attention. Even when viewing the same image, the model gains clarity on what it should perceive, enabling it to detect previously overlooked situations.
3. 🏛️ System Design: A Specialized Multi-Agent Architecture
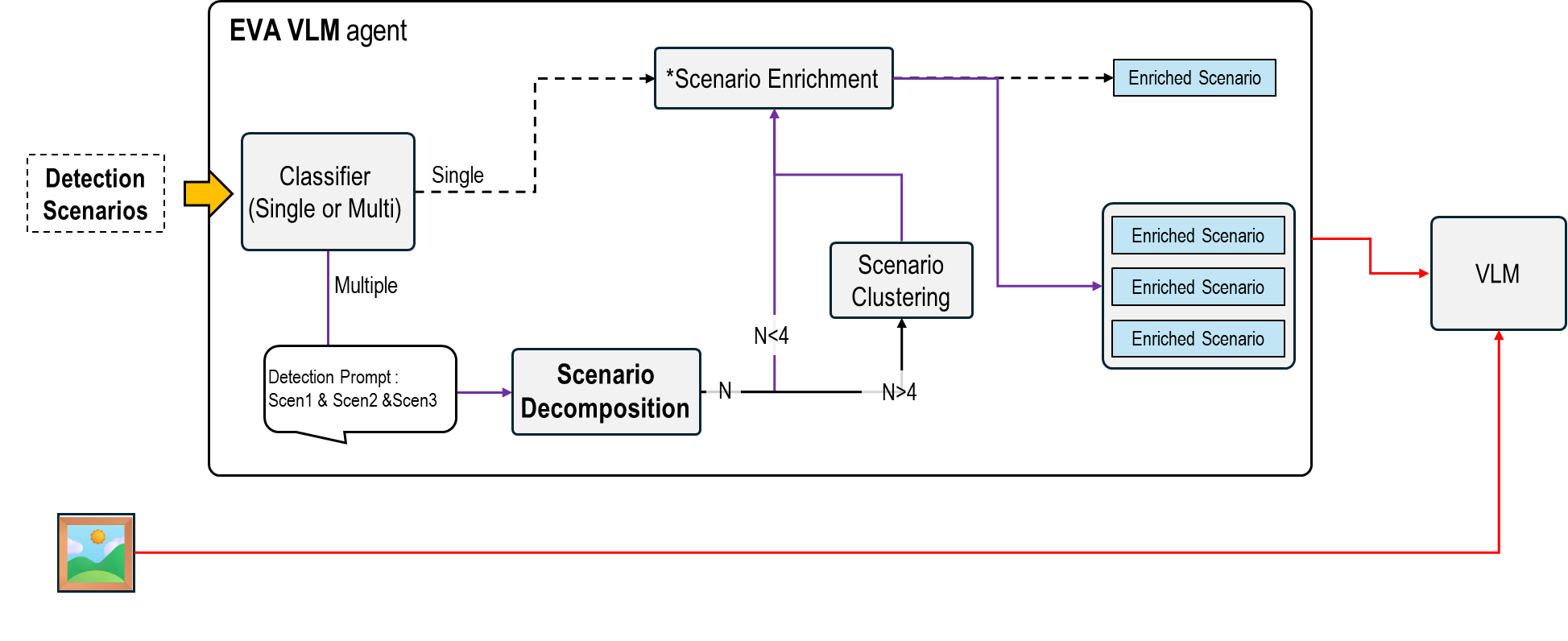
Overall Pipeline
The EVA Agent processes complex scenarios through the following five stages:
- Classifier (Single or Multi): Determines the number of scenarios in the input
- Scenario Decomposition: Splits multi-scenario inputs into individual scenarios
- Scenario Enrichment: Injects rich detection conditions into each scenario [4]
- Scenario Clustering: Groups similar scenarios when the count exceeds four
- Parallel Inference: Executes VLM inference in parallel and aggregates results (Conceptual illustration: a single image processed through four separate prompt paths)
Stage 1: Scenario Classification
The LLM analyzes the user-provided scenario description to determine whether it represents a single or multiple scenarios.
[e.g.]
"If a fire occurs, or someone falls, or a traffic accident is detected"
[LLM Prompt]
Analyze the following scenario description and determine whether it is
a single scenario or multiple scenarios:
"{user_input}"
[LLM Output]
{
"type": "multi",
"count": 3,
"scenarios": ["fire", "fall", "traffic accident"]
}
Comparison with Q₂E:
- Q₂E: Performs event decomposition from a single query like “2025 LA Fire”
- EVA: Performs scenario decomposition from compound queries like “fire or fall or traffic accident”
Stage 2: Scenario Decomposition
Just as Q₂E decomposes a complex query into Prequel / Current / Sequel, we decompose complex scenes into domain-specific directives.
[Q₂E Decomposition]
Query: "2025 LA Fire"
→ Prequel: "What could happen before?"
→ Current: "What happens during?"
→ Sequel: "What could be the outcome?"
[EVA Decomposition]
Query: "fire or fall or traffic accident"
→ Scenario 1: "Fire indicator detection"
→ Scenario 2: "Fall accident detection"
→ Scenario 3: "Traffic accident detection"
Stage 3: Scenario Enrichment
Comparison with Q₂E Refinement:
| Component | Q₂E | EVA |
|---|---|---|
| Input | Decomposed Event ("Building on Fire") | Decomposed Scenario ("Fire indicator detection") |
| Added Information | Temporal (2025) + Spatial (LA) + Event (Fire) | Domain Knowledge (visual features, detection criteria) |
| Output | "Building on Fire during 2025 LA Fire" | "Fire detection via refined detection criteria" |
| Purpose | Leverage LLM event knowledge | Focus VLM visual attention |
Enrichment Example (See also: Turning Simple User Requests into AI-Understandable Instructions)
| Aspect | Before (Simple) | After (Enriched) |
|---|---|---|
| Prompt | "Detect fire." | "Detection: Fire is present with visible smoke. Exception: Fire or smoke cannot be clearly identified due to camera angle." |
| VLM Behavior | Shallow scan of entire frame | Focused attention on color and texture features |
Stage 4: Scenario Clustering (When N > 4)
When the number of enriched prompts exceeds four, semantically similar scenarios are grouped to improve inference efficiency.
Clustering Rule:
IF N > 4:
Ask LLM to group scenarios by visual similarity
into a maximum of four groups
ELSE:
Process each scenario independently
[Example with many scenarios]
Input: ["fire", "smoke", "explosion", "fall", "collapsed person",
"traffic accident", "collision", "emergency vehicle"]
[LLM-based Semantic Grouping]
Group 1 (Fire-related): ["fire", "smoke", "explosion"]
Group 2 (Human safety): ["fall", "collapsed person"]
Group 3 (Traffic): ["traffic accident", "collision"]
Group 4 (Emergency response): ["emergency vehicle"]
→ Reduce 8 scenarios to 4 groups
→ Optimize VLM latency and memory usage
Stage 5: Parallel VLM Inference
Each enriched prompt is sent to the VLM in parallel.
[e.g.]
enriched_prompts = [Group1_prompt, Group2_prompt, Group3_prompt, Group4_prompt]
PARALLEL_EXECUTE:
FOR each prompt IN enriched_prompts:
result = VLM(frame=cctv_image, instruction=prompt)
results.append(result)
WAIT_ALL_COMPLETE
Key Differences:
- Q₂E analyzes a single video across multiple modalities (video, audio, text)
- EVA analyzes a single frame across multiple scenarios (fire, fall, traffic)
4. 📊 Case Study: Unified vs. Decomposed Scenarios
This is not about asking more questions—it is about how accurately the model understands the situation.
Using real EVA evaluation footage, we compared unified scenarios and decomposed multi-scenarios on the same complex video.
4.1. Test Scenario
A video containing three critical incidents played sequentially was evaluated using both approaches.

Unified Scenario Prompt
"If at least one emergency vehicle exists,
or a fire occurs,
or at least one person has fallen"
Decomposed Multi-Scenario Prompts
Each scenario includes enriched detection criteria and exceptions.
| Scenario | Detection Steps | Exceptions |
|---|---|---|
| Emergency Vehicle | • At least one vehicle present • At least one emergency vehicle identified | • No emergency vehicles • All vehicles are taxis • Police lights appear blue only • Lights not mounted on roof • Only headlights or brake lights visible |
| Fall / Traffic Accident | • At least one person present • Person is fallen or traffic accident occurs | • No fallen person • Only upper body visible • Lower body not visible |
| Fire / Smoke | • Fire present • Smoke detected | • No fire or smoke detected |
4.2. Experimental Results
| Scenario | Unified Prompt | Decomposed Prompts |
|---|---|---|
| Fallen Person | ✅ Detected | ✅ Detected |
| Emergency Vehicle | ✅ Detected | ✅ Detected |
| Fire | ❌ Missed | ✅ Detected |
| Overall Accuracy | 66.7% (2/3) | 100% (3/3) |
4.3. Detailed Analysis
1) Limitations of Unified Scenarios (Attention Interference)
VLM Output
Analysis:
✅ One fallen person detected (Scene 1)
✅ One emergency vehicle (police car) detected (Scene 2)
❌ No fire indicators detected
Result: One critical incident missed
Issues:
- Attention bias toward early scenes (people, vehicles)
- Subtle fire indicators (smoke, flame textures) ignored in favor of salient objects
2) Decomposed Scenario Detection Result
[Fire Detection Result]
⚠️ Fire detected
Detected visual features:
✓ Orange/red flames (Scene 3, bottom-right)
✓ Vertical gray smoke patterns
✓ Irregular bright region boundaries
Location: Bottom-right of frame
Confidence: 0.91
Decision: Fire confirmed (immediate dispatch required)
Why it worked:
- Specialization: Fire Agent focuses exclusively on fire-related features
- Interference Reduction: Other scenarios do not introduce perceptual noise
5. Conclusion: “The Depth of the Question Determines the Depth of Understanding”
This work leads to a clear conclusion. What limits VLM performance is not the number of parameters, but how we instruct the model to perceive the world.
Just as Q₂E improves retrieval accuracy by decomposing queries, we demonstrated that Scenario Decomposition enables VLMs to simultaneously and deeply understand multiple situations in complex CCTV monitoring environments.
Moving forward, we plan to extend this approach beyond static image analysis toward Temporal Event Decomposition, enabling models to reason over the temporal context of video streams.
(This post presents a creative adaptation of the Q₂E: Query-to-Event Decomposition methodology to solve Multi-Scenario Cognition challenges in vision-based tasks.)
References
[1] Shubhashis Roy Dipta, Francis Ferraro. "Q₂E: Query-to-Event Decomposition for Zero-Shot Multilingual Text-to-Video Retrieval." arXiv:2506.10202v2, 2025.
[2] Standley, T., Zamir, A., Chen, D., Guibas, L., Malik, J., & Savarese, S. "Which Tasks Should Be Learned Together in Multi-task Learning?" ICML 2020.
[3] Pratt, S., Covert, I., Liu, R., & Farhadi, A. "What Does CLIP Know About a Red Circle? Visual Prompt Engineering for VLMs." ICCV 2023.
[4] EVA Tech Blog: Turning Simple User Requests into AI-Understandable Instructions

