VLM에게 '멀티 태스킹'을 가르치는 법: 시나리오 분해를 통한 상황 인지 능력 고도화

EVA 핵심은 "화재", "낙상", "교통사고" 등 화면 속에서 동시 다발적으로 일어나는 위급 상황을 놓치지 않고 '이해' 하는 것입니다. 하지만 아무리 뛰어난 VLM(Vision-Language Model)이라도 한 번에 너무 많은 것을 물어보면 인지 능력이 급격히 떨어지는 현상이 발생합니다.[2,3]
본 포스트에서는 텍스트-비디오 검색 분야의 최신 연구인 Q₂E (Query-to-Event Decomposition)[1] 논문을 참고하여, VLM이 단일 화면 내의 복합적인 시나리오를 깊이 있게 인지하도록 만드는 '시나리오 분해(Scenario Decomposition)' 기법을 소개합니다.
1. 🚀 문제 : VLM의 인지의 병목
EVA Agent는 복잡한 도심 도로나 다중 이용 시설을 24시간 감시해야 합니다. 초기에는 VLM의 범용적인 능력을 믿고, 인간처럼 한 번에 모든 상황을 파악하길 기대했습니다.
[초기 접근: 통합 질의 (Unified Query)]
"이 CCTV 화면을 보고 화재, 사람 쓰러짐, 교통사고, 긴급차량 진입 여부를 모두 확인해서 알려줘."
하지만 결과적으로 모델은 '선택적 인지' 의 한계를 드러냈습니다. 예를 들면, 화면 중앙의 큰 버스는 잘 보지만, 그 뒤편에서 발생하는 화재 징후나 쓰러진 사람은 단순히 배경으로 치부해버릴 수 있습니다.
이는 모델의 Attention 메커니즘이 여러 타겟(Target)으로 분산되면서, 중요한 위험 신호에 대한 Contextual Understanding(맥락적 이해) 깊이가 얕아지기 때문에 발생하는 문제입니다.
2. 💡 해결책: Q₂E 기반의 인지 능력 확장
이 문제를 해결하기 위해 우리는 "복잡한 사건을 쪼개면(Decompose) 이해도가 높아진다"는 Q₂E 논문의 핵심 철학을 도입했습니다.
2.1. 논문의 통찰 (Q₂E: Query-to-Event)
논문은 "산불"이라는 단어 하나로 검색하는 것보다, 이를 "전조 -> 진행 -> 결과"라는 사건의 흐름으로 분해해서 모델에 주입했을 때, 모델이 해당 사건을 훨씬 더 풍부하게 이해하고 찾아낸다는 것을 증명했습니다.
2.2. EVA Agnet 도입 : Scenario Decomposition (시나리오 분해)
우리는 이 개념을 "Multi-Scenario Understanding(다중 시나리오 이해)"로 확장했습니다. VLM에게 한 번에 넓게 보라고 하는 대신, 각 시��나리오별로 깊게 볼 수 있는 '관점'을 부여하는 것입니다.
- Before (단일 시각): "화재, 사람 쓰러짐, 교통사고가 확인되면 알려줘" -> (모호함, 주의력 분산)
- After (다중 시각 분해):
- [화재 사건 시각]: "이미지의 픽셀 변화, 색상, 연기 질감에 집중해서 화재 징후가 있는지 봐줘."
- [안전 관제 시각]: "사람의 자세(Pose)와 주변 사물과의 관계를 보고 쓰러짐이 있는지 봐줘."
- [교통 관제 시각]: "차량 간의 충돌, 비정상적인 정차 위치를 보고 사고 여부를 판단해줘."
이렇게 질문을 분해(Decomposition)하면, VLM의 Visual Encoder는 각 질문에 맞는 Feature(특징)에 강하게 Attention을 활성화시킵니다. 즉, 같은 이미지를 보더라도 '무엇을 인지해야 하는가'가 명확해지면서 숨겨진 상황을 찾아내는 능력이 부여됩니다.
3. 🏛️ 시스템 구현: 전문화된 Multi-Agent 아키텍처
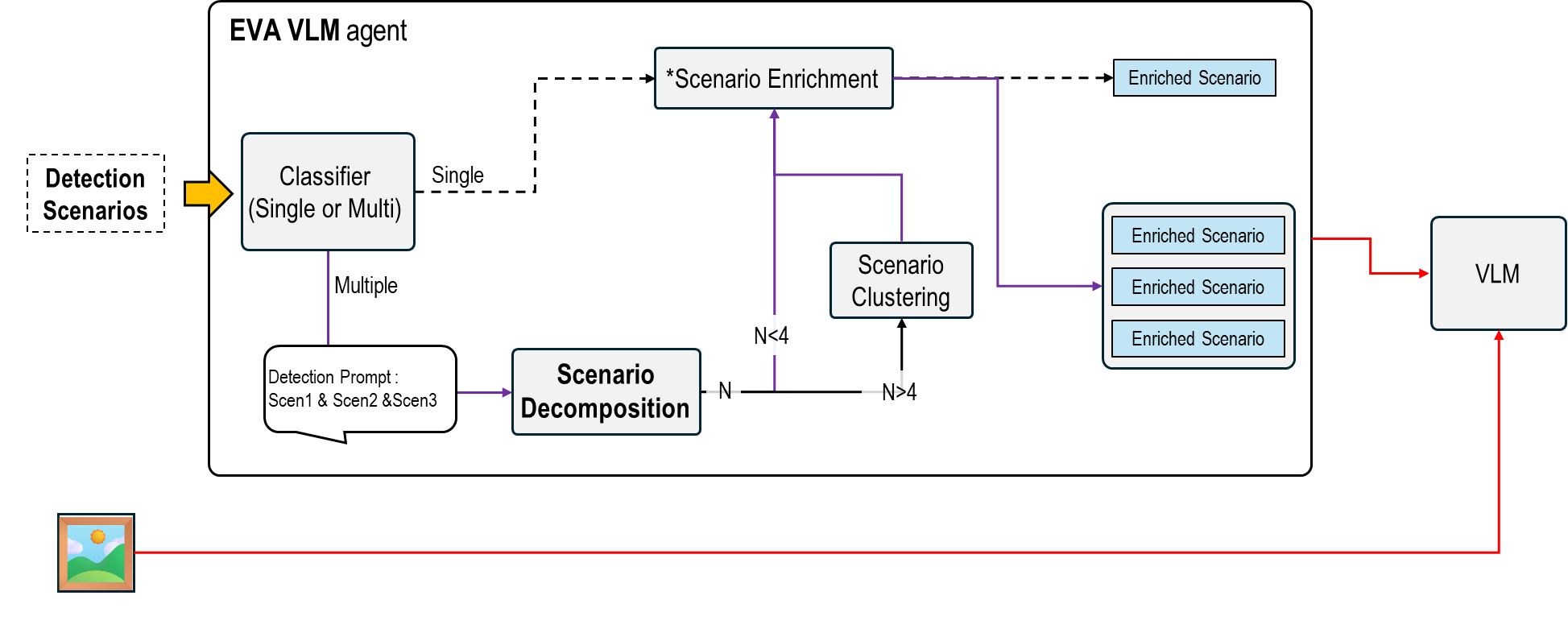
전체 파이프라인
EVA Agent는 다음 5단계로 복합 시나리오를 처리합니다.
- Classifier (Single or Multi): 입력된 시나리오 개수 판단
- Scenario Decomposition: Multi 시나리오인 경우 개별 시나리오로 분해
- Scenario Enrichment: 각 시나리오에 풍부한 탐지 조건 주입[4]
- Scenario Clustering: 시나리오 개수 N이 N>4인 경우 유사 시나리오 그룹핑
- Parallel Inference: 병렬 VLM 추론 및 결과 통합 (개념도 예시: 하나의 이미지가 4개의 서로 다른 Prompt 경로로 나뉘어 처리됨)
Stage 1: Scenario Classification
사용자로부터 받은 탐지 시나리오 설명을 LLM이 분석하여 Single/Multi 여부를 판단합니다.
[e.g.]
"화재가 발생한 경우거나, 사람이 쓰러진 경우이거나, 교통사고가 확인되는 경우"
[LLM Prompt]
다음 시나리오 설명을 분석하고, 단일 상황(Single)인지 복수 상황(Multi)인지 판단하세요:
"{user_input}"
[LLM 출력]
{
"type": "multi",
"count": 3,
"scenarios": ["화재", "낙상", "교통사고"]
}
Q₂E 방법론과 비교:
- Q₂E: "2025 LA Fire"라는 단일 쿼리를 받아 Event Decomposition 수행
- EVA: "화재 or 낙상 or 교통사고"라는 복합 쿼리를 받아 Scenario Decomposition 수행
Stage 2: Scenario Decomposition
Q₂E 방법론이 하나의 복잡한 쿼리를 Prequel/Current/Sequel로 분해한 것처럼, 우리는 복잡한 화면을 도메인별 관찰 지시(Domain-specific Directives)로 분해합니다.
[Q₂E의 Decomposition]
Query: "2025 LA Fire"
→ Prequel: "What could happen before?"
→ Current: "What happens during?"
→ Sequel: "What could be the outcome?"
[EVA의 Decomposition]
Query: "화재 or 낙상 or 교통사고"
→ Scenario 1: "화재 징후 탐지"
→ Scenario 2: "낙상 사고 탐지"
→ Scenario 3: "교통 사고 탐지"
Stage 3: Scenario Enrichment
Q₂E의 Refinement와의 비교:
| 구성 요소 | Q₂E | EVA |
|---|---|---|
| 입력 | Decomposed Event ("Building on Fire") | Decomposed Scenario ("화재 징후 탐지") |
| 추가 정보 | Temporal (2025) + Spatial (LA) + Event (Fire) | Domain Knowledge (시각적 특징, 탐지 기준) |
| 출력 | "Building on Fire during 2025 LA Fire" | "구체화 탐지 조건 분석으로 화재 탐지 여부" |
| 목적 | LLM의 Event Knowledge 활용 | VLM의 Visual Attention 집중 유도 |
Enrichment 예시 (참고: Turning Simple User Requests into AI-Understandable Instructions)
| 비교 항목 | Before (단순 분해) | After (Enrichment) |
|---|---|---|
| 프롬프트 | "화재를 탐지하세요" | "탐지: 연기가 감지되고 화재가 발행한 경우 예외: 카메라 각도로 인해 연기/화재가 확실히 확인되지 않는 경우" |
| VLM 반응 | 화면 전체를 얕게 스캔 | 색상·질감 특징에 Attention 집중 |
Stage 4: Scenario Clustering (N>4인 경우)
Enriched Prompt가 4개를 초과하면, 의미적으로 유사한 시나리오를 그룹핑하여 병렬 추론 효율을 높입니다.
Clustering 조건:
IF N > 4:
LLM에게 요청: "이 시나리오들을 시각적 유사성 기준으로
최대 4개로 Grouping"
ELSE:
각 시나리오를 독립적으로 처리
[시나리오가 많은 경우 예시]
Input: ["화재", "연기", "폭발", "낙상", "쓰러진사람",
"교통사고", "충돌", "긴급차량"] // 8개
[LLM 기반 Semantic Grouping]
Group 1 (화재 관련): ["화재", "연기", "폭발"]
Group 2 (인명사고 관련): ["낙상", "쓰러진사람"]
Group 3 (교통사고 관련): ["교통사고", "충돌"]
Group 4 (긴급 대응): ["긴급차량"]
→ 8개 시나리오를 4개 그룹으로 압축
→ VLM Latency 최적화 (메모리 효율 ↑)
Stage 5: Parallel VLM Inference
각 Enriched Prompt를 VLM에 병렬로 전달합니다.
[e.g.]
enriched_prompts = [Group1_prompt, Group2_prompt, Group3_prompt, Group4_prompt]
PARALLEL_EXECUTE:
FOR each prompt IN enriched_prompts:
result = VLM(frame=cctv_image, instruction=prompt)
results.append(result)
WAIT_ALL_COMPLETE
→ Q₂E의 Multi-modal Description 생성과 유사한 병렬 처리 구조
핵심 차이점:
- Q₂E: 하나의 비디오를 여러 모달(Video, Audio, Text)로 분석
- EVA: 하나의 화면을 여러 시나리오(Fire, Fall, Traffic)로 분석
4. 📊 실제 사례: 통합 vs 분해 시나리오 비교
단순히 질문을 여러 번 하는 것이 아닙니다. 핵심은 "모델이 상황을 얼마나 더 정확하게 인지하게 되었는가"입니다.
실제 EVA 평가 영상을 활용하여, 동일한 복합적인 상황이 포함된 영상에서 통합 시나리오와 분해 시나리오의 인지 차이를 비교했습니다.
4.1.테스트 시나리오
3가지 위급 상황이 순차적으로 재생되는 영상에 대해 "통합 시나리오" VS "분해된 멀티 시나리오" 로 모든 상황을 정확히 인지하는지 비교합니다.

통합 시나리오 프롬프트
"1대 이상의 긴급차량이 존재하거나,
화재가 발생하거나,
넘어진 사람이 최소 1명 이상 존재하는 경우"
분해된 멀티 시나리오 프롬프트
각 시나리오별로 Enrich된 "탐지 기준 & 예외 조건"을 명시합니다.:
| 시나리오 | Detection Steps | Exceptions |
|---|---|---|
| 긴급차량 탐지 | • 차량이 1대 이상 존재 • 최소 1대 이상의 긴급차량 확인 | • 모든 차량이 긴급차량 아님 • 모든 차량이 택시 • police light가 파란색만 보임 • police light가 지붕에 없음 • 헤드라이트/브레이크등만 빛남 |
| 사람 쓰러짐 교통사고 | • 사람이 1명 이상 존재 • 사람이 넘어진 상태 또는 교통사고 발생 | • 넘어진 사람이 없음 • 상반신(머리·허리/등)만 보임 • 하반신(다리·발)이 보이지 않음 |
| 화재/연기 탐지 | • 화재가 발생함 • 연기가 감지됨 | • 연기나 화재가 감지되지 않음 |
4.2. 실험 결과
| 시나리오 | 통합 시나리오 (Unified Prompt) | 분해된 멀티 시나리오 (Decomposed Prompts) |
|---|---|---|
| 사람 쓰러짐 | ✅ 탐지 성공 | ✅ 탐지 성공 |
| 긴급차량 확인 | ✅ 탐지 성공 | ✅ 탐지 성공 |
| 화재 확인 | ❌ 탐지 실패 | ✅ 탐지 성공 |
| 종합 정확도 | 66.7% (2/3) | 100% (3/3) |
4.3. 상세 분석
1) 통합 시나리오의 한계 (Attention 간섭)
VLM 응답
분석 결과:
✅ 쓰러진 사람 1명 확인됨 (Scene 1)
✅ 긴급차량(경찰차) 1대 확인됨 (Scene 2)
❌ 화재 징후 없음
판정: 위급 상황 1건 미탐지
문제점:
- Attention 편향: 앞선 장면(사람, 차량)에 인지 자원이 집중되어 후속 상황을 간과함.
- 시각적 특징 소홀: 화재 특유의 미세한 픽셀 변화(연기, 불꽃)보다 명확한 객체(사람, 차) 위주로 탐색하는 경향 보임.
2) 분해된 시나리오 탐지 결과
[화재 탐지 결과]
⚠️ 화재 감지
탐지된 시각적 특징:
✓ 주황색/빨간색 불꽃 확인 (Scene 3, 우측 하단)
✓ 회색 연기 수직 상승 패턴 확인
✓ 불규칙한 경계의 밝은 영역 확인
위치: 화면 우측 하단 영역
신뢰도: 0.91
판정: 화재 발생 (즉시 소방 출동 필요)
탐지 요인:
- 전문화(Specialization): Fire Agent가 화재 관련 Feature(색상, 패턴)에만 Visual Encoder의 자원을 집중함.
- 간섭 차단: 다른 위급 상황 정보가 노이즈로 작용하지 않아 오탐 및 미탐율 감소.
5. 결론: "질문의 깊이가 이해의 깊이를 결정한다"
이번 연구 및 개발 과정을 통해 얻은 결론은 명확합니다. VLM의 성능을 제한하는 것은 모델 자체의 파라미터 수가 아니라, 우리가 모델에게 세상을 어떻게 보라고 지시하는 '방법'에 있었다는 점입니다.
Q₂E 방법론이 텍스트 검색의 정확도를 높이기 위해 쿼리를 분해했듯, 우리는 CCTV 관제라는 복잡한 도메인에서 시나리오 분해(Scenario Decomposition)를 통해 VLM에게 다중 상황을 동시에, 그리고 깊이 있게 인지할 수 있는 능력을 성공적으로 부여했습니다.
앞으로 우리는 이 방법론을 더욱 고도화하여, 정적 이미지 분석을 넘어 비디오의 시간적 맥락까지 이해하는 Temporal Event Decomposition으로 확장해 나갈 계획입니다.
(본 포스팅은 Q₂E: Query-to-Event Decomposition 논문의 방법론을 Vision Task의 Multi-Scenario Cognition 문제 해결에 창의적으로 적용한 사례입니다.)
References
[1] Shubhashis Roy Dipta, Francis Ferraro. "Q₂E: Query-to-Event Decomposition for Zero-Shot Multilingual Text-to-Video Retrieval." arXiv:2506.10202v2, 2025.
[2] Standley, T., Zamir, A., Chen, D., Guibas, L., Malik, J., & Savarese, S. "Which Tasks Should Be Learned Together in Multi-task Learning?" ICML 2020.
[3] Pratt, S., Covert, I., Liu, R., & Farhadi, A."What Does CLIP Know About a Red Circle? Visual Prompt Engineering for VLMs." ICCV 2023.
[4] EVA Tech Blog: Turning Simple User Requests into AI-Understandable Instructions

