사용자 피드백 데이터 기반 Instruction Tuning을 통한 성능 고도화


캠퍼스, 안전을 넘어 지능을 갖다: EVA와 함께하는 Postech Living Lab 프로젝트로 이재찬 군(지도 교수 고영명 님)과 협동 연구한 주제입니다.
🎯 서론: 피드백을 '사후 보정'에서 '사고 능력 강화'로 전환하다
EVA가 이미지를 판단할 때, 운영자들은 "이 경우는 안전조끼가 맞아. 왜 헷갈린 거지?" 또는 "여기서는 경보가 나야 하는 것 아닌가?"와 같은 구체적인 피드백을 제공합니다. 이 피드백에는 단순한 정오답을 넘어, 사람이 판단에 이른 이유와 문맥이 담겨 있습니다.
그동안 EVA는 이러한 피드백을 별도의 Vector DB에 저장하여 유사 상황 발생 시 Alert 여부를 보정하는 방식으로 활용해 왔습니다. 이 방식은 신속한 적용이 가능하다는 장점이 있었지만, 모델 자체의 추론 능력을 개선하지 못하고 오류를 사후적으로 필터링하는 구조적 한계를 가지고 있었습니다.
우리는 이 문제를 근본적으로 해결하기 위해 접근 방식을 완전히 바꿨습니다. 사용자 피드백을 단순한 오류 보고가 아니라, 모델이 추론 과정에 직접 활용하여 시각적 사고(Visual Reasoning) 능력을 강화할 수 있는 Instruction 데이터로 재구성한 것입니다.
이 글에서는 사용자 피드백 데이터를 활용한 VLM 기반 Instruction Tuning이 기존의 Vector DB 중심 접근의 한계를 어떻게 극복하고, 모델의 시각적 추론 능력을 어떻게 개선하는지를 중심으로 이야기하려고 합니다.
1. 기존 Vector DB 중심 접근의 구조적 과제와 개선 필요성
EVA는 오탐 피드백을 벡터로 저장하고, 새로운 이미지가 들어오면 유사 사례를 검색하여 Alert 여부를 보정하는 방식을 사용해 왔습니다. 이 방식은 빠르고 간단하게 적용 가능하다는 장점이 있었으나, 모델 자체의 지능적인 판단 능력을 향상시키는 데는 다음과 같은 구조적 과제가 존재했습니다.
-
(1) 사례 기반 의존성: Vector DB는 과거에 저장된 사례에만 의존하므로, 시스템 운영 중 새로운 유형의 복잡한 사례(Hard Case) 가 등장하면 일반화하여 대응하기 어렵습니다.
-
(2) 본질적인 모델 추론 능력의 한계: 보정 로직이 필터링 단계에서만 작동하므로, 모델 자체는 오류 패턴을 학습하지 못하고 동일한 시각적 혼동을 반복할 가능성이 남아있습니다.
-
(3) 복잡한 시각적 문맥 이해 부족: 조명 변화, 색상 차이, 반사 스트라이프 유무 등 산업 현장 특유의 미묘한 시각적 변수를 모델이 스스로 이해하고 판단에 통합하는 능력이 미흡했습니다.
요약하면, 기존 방식은 "결과를 사후적으로 보정하는 도구"로서의 역할은 충실했지만, 모델에게 왜 잘못 판단했는지, 어떻게 올바르게 판단해야 하는지를 학습시켜 스스로 일관성 있는 판단을 내릴 수 있도록 돕지는 못하는 구조였습니다.
2. 새로운 방향성: VLM 기반 Instruction Tuning과 프로젝트 목표
기존 Vector DB 방식이 오류를 사후적으로 보완하는 데 집중했다면, 새로운 접근은 모델이 스스로 규칙을 이해하고 일관된 결론을 내릴 수 있도록 만드는 데 초점을 맞춥니다. 이 문제를 해결하기 위한 선택지가 바로 VLM(Vision-Language Model) 기반 Instruction Tuning입니다.
VLM은 이미지와 텍스트를 함께 이해하는 구조를 갖고 있으며, 여기에 지시문(Instruction)과 정답을 함께 학습시키면 모델은 단순 검출을 넘어 맥락 기반 시각적 추론 능력을 갖추게 됩니다. 즉, "무엇을 봐야 하는가"뿐 아니라 "어떻게 판단해야 하는가"를 학습할 수 있게 되는 것입니다.
이번 프로젝트는 이러한 특성을 실제 산업 환�경에서 검증하기 위해 설계되었으며, 핵심 목표는 다음과 같습니다.
- 오탐·미탐 피드백을 QA Instruction 데이터셋으로 재구성합니다.
- 이 데이터를 바탕으로 EVA 기반 VLM을 Instruction Tuning 합니다.
- 튜닝된 모델이 기존 대비 실제 추론 능력이 얼마나 향상되는지를 정량적으로 검증합니다.
이번 프로젝트는 단순히 성능 개선을 넘어, 모델이 규칙을 이해하고 스스로 판단할 수 있는 구조적 개선이 가능한지를 증명하는 과정이었습니다.
3. 💡 방법론
3.1. Phase 1: Baseline 구축 및 Failure Collection
본 프로젝트의 첫 단계에서는 EVA에서 기존에 사용하던 VLM인 Qwen2.5-VL-32B-Instruct를 기준 모델(Baseline)로 설정하고, Kaggle PPE Dataset을 활용하여 오탐/미탐 사례 총 152건의 Hard Case를 수집하였습니다.
- 오탐(False Positive): 안전장비를 착용했음에도 불구하고 Alert가 발생한 사례
- 미탐(False Negative): 안전장비를 착용하지 않았음에도 Alert가 발생하지 않은 사례
이러한 실패 사례는 단순한 정답 여부를 넘어, 모델이 실제로 어떤 장면에서 시각적 혼동을 겪는지를 드러내는 중요한 근거가 됩니다.
수집된 Hard Case에 대해서는 사람이 직접 이미지의 상황을 설명하고, 모델이 왜 실패했는지에 대한 맥락을 텍스트로 보완하였습니다. 이 과정은 단순한 오류 확인을 넘어, 모델이 어려워하는 시각적 패턴과 판단 포인트를 체계적으로 확보하기 위한 작업이었습니다.
오탐 데이터 피드백 예시
시나리오 : "안전모와 안전조끼 중 하나라도 미착용 상태인 작업자가 있다면 시 경보 (Alert)를 발동해 주세요."

실패 유형 : 오탐
피드백 : 이미지에 등장하는 모든 작업자들은 안전조끼와 안전모를 착용하고 있음. 5명 중 4명은 검은색 안전모를 착용하고 있으며, 1명은 흰색 안전모를 착용하고 있음.

실패 유형 : 미탐
피드백 : 이미지 상에는 네 명의 작업자가 있으며, 왼쪽에서 세 번째에 있는 작업자는 안전조끼는 입었지만 안전모를 쓰고 있지 않음.
3.2. Phase 2: QA Instruction Dataset 구축
Phase 2에서는 수집된 피드백을 단순 텍스트 정보로 두지 않고, 모델의 추론 능력을 직접 강화할 수 있는 QA Instruction 데이터셋으로 확장하는 작업을 진행하였습니다. 이 단계는 모델이 "무엇을 잘못했는지" 뿐 아니라 "왜 잘못되었는지, 어떻게 판단해야 하는지"까지 학습하도록 만드는 핵심 과정입니다.
(1) 데이터셋 구축 절차: 반-자동화 방식(Semi-Automated Construction)
Holmes-VAD (Zhang et al. 2024)에서 사용한 반자동 Instruction 생성 방식을 참고하여 다음과 같은 프로세스를 적용하였습니다.
- 오탐/미탐 이미지 + 사람이 작성한 피드백을 강력한 VLM에 입력합니다. (본 프로젝트에서는 Gemini-2.5-flash를 사용)
- 사전에 정의한 4가지 질문 유형(A-D) 에 따라 QA 초안을 생성합니다.
- 연구자가 초안을 검토하여 불필요한 설명을 제거하고, 실제 판단 규칙에 맞도록 수정합니다.
이 과정을 통해 단순 피드백을 구조화된 Instruction 형태로 바꿨으며, 기존 152건의 피드백으로부터 총 518개의 QA 데이터를 생성하였습니다.
(2) 4가지 질문 유형(A–D)
수집된 피드백은 다음 네 가지 유형으로 변환되었습니다. A는 사실 확인 중심, B, C, D는 모두 추론 강화 유형입니다. 각 유형은 모델이 실제로 놓쳤던 판단 요소를 보완하도록 설계되었습니다.
A. 기본 사실 확인 (Fact Verification)
가장 직접적인 수정 유형으로, 모델이 잘못 판단한 부분을 바로잡아줍니다. 문제의 핵심을 명확하게 짚어주기 때문에 베이스라인 교정에 효과적입니다.
질문 : "안전모와 안전조끼 중 하나라도 미착용 상태인 작업자가 있다면 시 경보 (Alert)를 발동해 주세요."
답변 : "이미지에 등장하는 작업자는 안전모를 착용하고 있지만 안전 조끼를 착용하고 있지 않습니다. 따라서 경보��를 울립니다"
B. 비교·대조 추론 (Comparison & Contrast Reasoning)
비슷해 보이지만 실제로는 다른 시각적 패턴을 구별하도록 학습시키는 유형입니다. 안전조끼 vs 일반 옷, 반사띠 유무 등 미묘한 차이를 설명하는 데 활용합니다.
질문 : "안전 규정을 준수하고 있는 인물과 그렇지 않은 인물을 구별하여 어떤 차이점이 있는지 설명하세요."
답변 : "가운데에 있는 작업자는 검은색 안전모를 착용했지만 안전조끼는 입지 않았습니다. 이 작업자는 주황색 티셔츠만 입고 있으며, 다른 작업자들의 안전조끼와 달리 반사 테이프가 없고 몸통과 팔 소매 사이에 구분되는 선이 없습니다."
C. 반사실적·가설적 추론 (Counterfactual / Hypothetical Reasoning)
"만약 이 사람이 정상 착용자로 판단되려면 무엇이 달라져야 하는가?"와 같은 조건 변화 기반 추론을 통해 시각적 근거를 더 깊이 이해하도록 돕습니다.
질문 : "만약 이 사람이 '안전 조끼 착용자'로 판단되어야 한다면, 현재 이미지에서 어떤 시각적 요소가 변경되어야 합니까?"
답변 : "이 사람을 '안전 조끼 착용자'로 판단하려면, 우선 옷에서 소매가 없어져야 합니다. 그리고 옷의 색상이 형광 노란색과 같은 밝은 색으로 바뀌고 어깨나 허리 라인에 은색 반사 스트라이프가 추가되어야 합니다."
D. 실패 원인 분석 (Failure Analysis & Self-Diagnosis)
모델이 한 판단 중 "추론은 맞지만 최종 결론이 틀림"과 같은 추론-행동 불일치 오류를 스스로 발견하고 설명하도록 학습하는 유형입니다. 모델의 일관성 강화에 매우 중요한 역할을 합니다.
질문 : "모델이 '안전조끼는 착용하지 않은 상태'임을 올바르게 추론했음에도, 최종적으로 (Alert : False) 로 결론내렸습니다. 이 추론의 문제점은 무엇이며, 올바른 판단은 무엇입니까?"
답변 : "모델이 '안전조끼 미착용'으로 인한 '규정 미준수'를 텍스트로 명확히 설명했음에도, (Alert: False)라는 모순되는 최종 행동을 취했습니다. 이는 치명적인 '추론-행동 불일치' 오류입니다. 올바른 출력은 (Alert : True) 입니다."
3.3. Phase 3: VLM Fine-Tuning
Phase 3에서는 앞서 구축한 QA Instruction 데이터셋을 활용하여 EVA에서 사용 중인 VLM 모델을 실제로 튜닝하였습니다. 이 단계는 모델이 규칙을 더욱 정확하게 이해하고 일관된 판단을 내릴 수 있도록 만드는 과정입니다.
(1) 대상 모델 및 적용 환경
Qwen2.5-VL-32B-Instruct는 현재 EVA에서 사용될 수 있는 모델이기 때문에, 실제 서비스 개선 효과를 직접 확인할 수 있다는 점에서 실험 대상으로 선정하였습니다. 또한 학습 환경의 제약을 고려해, 모델의 메모리 사용량을 줄이기 위한 양자화(Quantization) 와 QLoRA를 적용하였습니다.
(2) 튜닝 기법: LoRA (Low-Rank Adaptation)
전체 모델 파라미터를 다시 학습시키는 대신, 필요한 부분만 추가적인 저차원 가중치(LoRA 모듈) 로 보완하는 방식입니다.
원래 모델의 거대한 가중치�는 그대로 유지하면서 특정 작업에 필요한 부분만 작은 가중치로 미세 조정 이 방식은 학습 비용을 크게 줄이면서도 성능 향상 효과를 얻을 수 있다는 장점이 있습니다.
(3) 학습 방법: Supervised Fine-Tuning
Fine-tuning에서는 실패 사례 이미지와 QA Instruction을 함께 입력으로 사용했습니다.
- Input: 탐지 실패 이미지 & 해당 이미지에 대응하는 QA Instruction
- Objective: 이미지와 질문이 주어졌을 때 정답 텍스트를 한 토큰씩 정확하게 생성하도록 학습
이 단계에서는 모델이 시각 정보와 규칙 기반 질의를 조합하여 정확한 판단과 설명을 생성할 수 있도록 지도 학습을 적용하였습니다.
4. 📈 주요 인사이트 및 성능 벤치마크
4.1. 비교 대상 모델 정의
이번 실험에서는 하나의 베이스라인 모델(Qwen2.5-VL-32B-Instruct)에 서로 다른 범위의 데이터를 적용해 성능 차이를 비교했습니다.
| 모델 | 설명 |
|---|---|
| Baseline | 아무런 추가 학습을 하지 않은 원본 모델. |
| Model A | 사실 확인 질문(A) 만을 사용��해 튜닝한 모델. → 예: "안전모를 착용했습니까?"처럼 단순한 판단 중심 |
| Model ABCD | 사실 확인(A)에 더해 비교/대조(B), 가정(C), 실패 원인 분석(D) 까지 포함한 다양한 질문으로 튜닝한 모델. → 왜 그렇게 판단하는지, 어떤 경우에 달라지는지까지 학습 |
A는 단순 사실 중심 모델, ABCD는 풍부한 추론·맥락 기반 모델입니다.
4.1. 발견한 주요 인사이트
✔ RQ1. 피드백 기반 Instruction Tuning은 실제 성능을 높일까?
결과는 분명합니다. Model A와 Model ABCD 모두 Baseline보다 높은 성능을 기록했습니다. 즉, 피드백 데이터를 질문·답변 형태로 정리하여 학습시키면 모델의 PPE 판단 능력이 확실히 향상됨을 확인할 수 있었습니다.
✔ RQ2. 단순 사실 질문만으로 충분할까?
단순 사실 질문만으로는 한계가 있습니다.
- Model A (사실 질문만 학습): 착용 여부를 대부분 잘 판단하지만, 지나치게 긍정적으로 판단하는 경향이 있어 오탐이 88건 발생
- Model ABCD (추론 질문 포함): 비교·대조, 근거 설명, 가정 상황 등 다양한 추론 패턴을 학습하며 오탐을 17건으로 크게 줄임
이를 통해 알 수 있듯, 단순히 맞다/틀리다만 학습시키는 것보다, 왜 그런 판단이 필요한지까지 포함하여 학습시킬 때 모델이 훨씬 안정적이고 신뢰성 있는 판단을 내릴 수 있음을 확인했습니다.
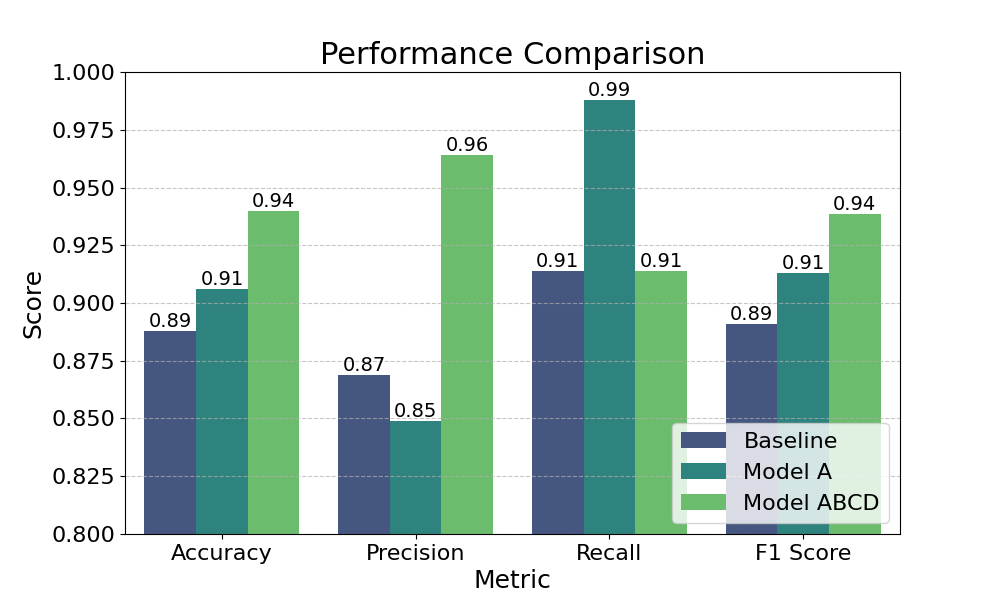
4.2. 성능 벤치마크
총 1,000장의 테스트 이미지(착용 500, 미착용 500)로 평가했습니다.
📊 정량 성능 요약
| 모델 | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|
| Baseline | 0.89 | 0.87 | 0.91 | 0.69 |
| Model A | 0.91 | 0.85 | 0.99 | 0.91 |
| Model ABCD | 0.94 | 0.96 | 0.91 | 0.94 |
Model ABCD가 전반적으로 가장 좋은 지표를 기록했습니다.
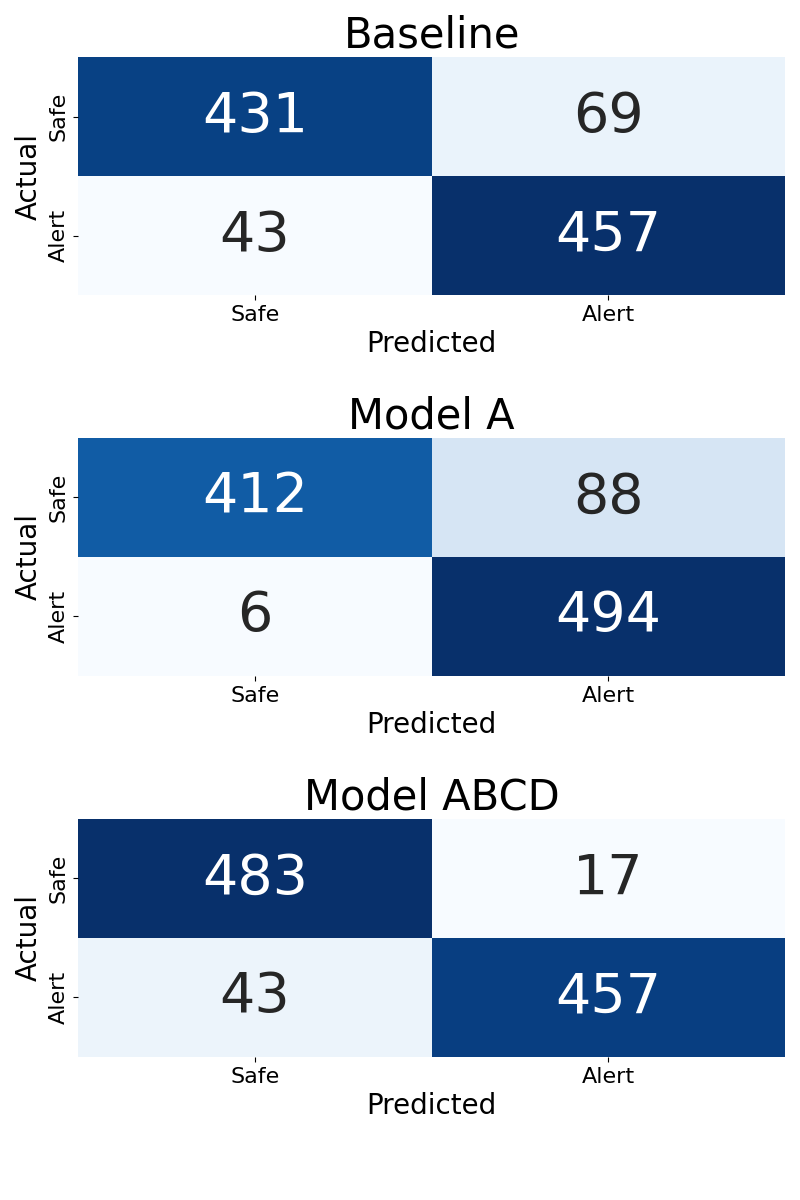
🚫 오탐(False Positive) 감소 효과
| 구분 | Baseline | Model A | Model ABCD |
|---|---|---|---|
| 오탐 발생 건수 | 69건 | 88건 | 17건 |
Model A는 착용하지 않은 상태를 잘못 판단하는 경우가 많았지만, Model ABCD는 다양한 추론 학습으로 이러한 오류를 대부분 바로잡았습니다. 이를 통해 추론형 질문 학습이 모델의 판단 신뢰도를 높이는 데 효과적임을 확인할 수 있습니다.
5. 결론
본 프로젝트에서는 EVA에서 발생하는 오탐·미탐 문제를 해결하고, 모델의 복합 조건 판단 능력을 향상시키기 위해 피드백 기반 VLM Instruction Tuning을 적용했습니다.
실험과 분석을 통해 얻은 주요 결론은 다음과 같습니다.
-
피드백 데이터를 Instruction 형태로 재가공하여 학습시키면 모델 성능이 향상됩니다.
QA Instruction으로 변환된 피드백은 단순 필터링과 달리 모델 내부 추론 능력 자체를 개선합니다. Baseline 대비 F1-score와 Precision 모두 눈에 띄게 상승했습니다. -
추론형 질문을 포함한 학습이 단순 사실 확인보다 더 큰 효과를 냅니다.
비교·대조, 근거 설명, 가정 상황 등의 질문을 학습한 Model ABCD는 오탐을 크게 줄이고, 실제 산업 환경에서 신뢰성 높은 판단을 가능하게 했습니다. -
Hard Case 학습을 통한 모델 안정성 강화
기존 Vector DB 방식이 사례 기반 보완에 그쳤다면, Instruction Tuning을 통해 모델이 새로운 유형의 시각적 혼동에도 능동적으로 대응할 수 있도록 개선되었습니다.
종합하면, 피드백 데이터를 기반으로 VLM을 Instruction Tuning하는 접근이 실제 산업 환경에서 모델의 추론 능력과 판단 신뢰도를 동시에 높일 수 있음을 입증하였습니다.
특히, 단순 정답 학습을 넘어서 "왜(Why)"와 "만약(What-if)" 사고 과정을 포함한 학습이 효과적임을 확인함으로써, 중요한 시사점을 제공합니다.
참고 자료
- Holmes-VAD (Zhang et al. 2024)
- https://www.kaggle.com/datasets/lbquctrung/worksite-safety-monitoring-dataset

