Eliminating False Positives in Human Detection Using Pose Estimation

Introduction
“There’s a person over there!” Our AI vision system confidently reported. Yet all we saw on the screen was an empty chair with a coat draped over it.
Human detection technology has advanced rapidly, but the real world is far more chaotic than polished demo videos. In the environments we focus on, the problem becomes even more noticeable:
- 🏢 Office: empty chairs with jackets
- 🔬 Laboratory: lab coats and protective clothing hanging on chairs
- 💼 Work areas: vacant meeting rooms and lounges
Such false positives aren’t just “slightly wrong” results. They directly degrade system trust and efficiency.
For example:
- Energy-saving systems may misjudge how many people are present and waste power.
- Security systems may focus on “phantom personnel” and waste monitoring resources.

Example: an empty chair mistakenly detected as a seated human
False Positive Challenges in VLM-based Vision Systems
In intelligent video analytics powered by Vision-Language Models (VLMs), false human detection is a frequent and critical issue.
Here are the most common patterns:
Pattern 1: Empty chairs detected as people
- Detector misinterprets chair backrests as human torsos
- Bias learned from data: “people usually sit on chairs”
- Incorrectly passes the result to VLM → “A person is working at the desk”
Pattern 2: Coats or clothing mistaken as humans
- Thick coats or lab coats hanging on chairs appear human-shaped
- Model overfits pattern: “humans wear clothes”
- VLM → “A staff member is standing here” (but it’s just a coat!)
Pattern 3: Mannequins or posters
- Similar silhouettes or textures to actual people
- No context to distinguish static models from humans
We needed a fundamental solution.
To address this, EVA introduces a verification stage between detection and VLM: Pose Estimation. Below, we share how we tackled the problem and the impact.
From Detection to Understanding
Let’s start by looking at the entire pipeline.
Intelligent Vision Analysis Pipeline
EVA’s vision solution operates in three core stages:
[Stage 1: Object Detection]
Image/Video → OmDet-Turbo → Detect object classes & locations
↓
[Stage 2: Verification & Filtering] ← 🎯 Focus of this article!
Only detected “person” objects → Verified with Pose Estimation
↓
[Stage 3: High-level Understanding]
Verified detections → VLM analysis → Semantic insight & response
↓
"Two customers are browsing the products."
Why Intermediate Filtering Matters
VLMs are powerful but expensive (compute-wise). More importantly: garbage in → garbage out.
Even the best VLM will produce flawed results when fed incorrect detections.
Thus, before anything reaches the VLM, we must ensure:
| Goal | Description |
|---|---|
| Accuracy | Remove objects that are not real humans |
| Efficiency | Reduce unnecessary VLM calls to save GPU resources |
Pose Estimation allows us to accomplish both simultaneously.
Without filtering?
Scenario: retail store monitoring
❌ Without Pose Verification:
Detected → "3 humans"
→ VLM: "3 customers in the store"
→ Actual: 1 customer + 2 mannequins
→ Wrong analytics + wasted compute
✅ With Pose Verification:
Pose check → Only 1 object has valid human joints
→ VLM analyzes only the real human
→ Correct analytics + reduced GPU cost
Key insight: Verify cheaply before processing expensively.
What Is Pose Estimation?
Pose Estimation identifies human joints (keypoints) in images or videos.
It’s like seeing the skeletal structure behind the person.
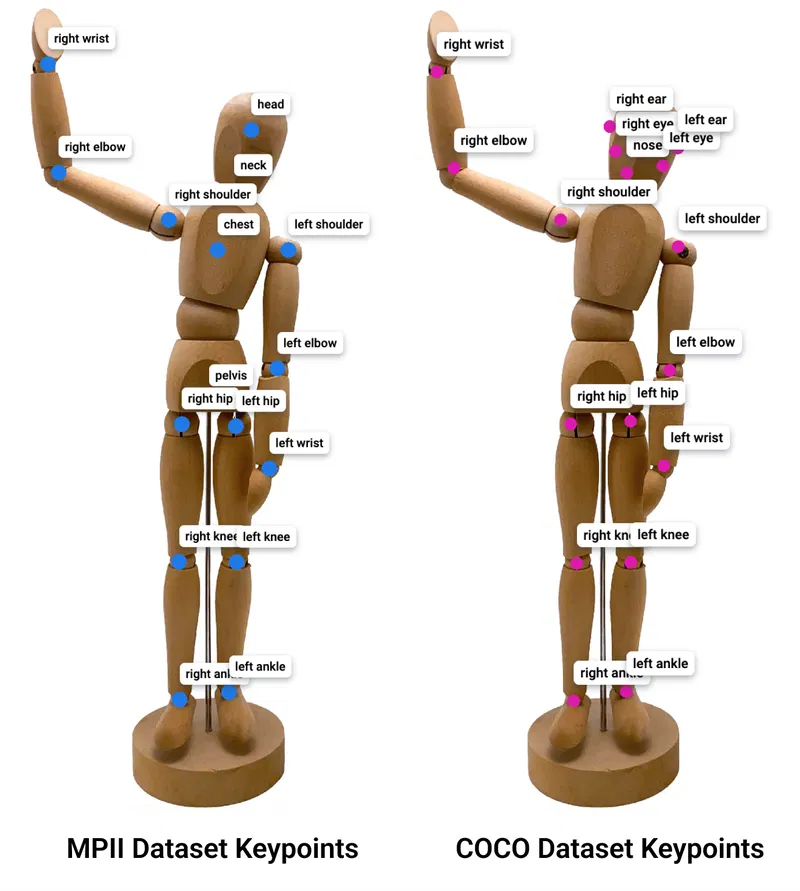
Source: https://supervisely.com/blog/human-pose-estimation/
Human image → AI → Detect 17 keypoints:
Nose, Eyes, Ears, Shoulders, Elbows, Wrists,
Hips, Knees, Ankles (left & right each)
These 17 keypoints form the structure of a real human body.
The difference between humans and false positives
| Target | Visual Similarity | Keypoints | Result |
|---|---|---|---|
| 🟢 Real human | High | Strong & complete | Valid |
| 🔴 Chair | Medium | None or fragmented | Invalid |
| 🔴 Chair + coat | High | Unnatural pattern | Invalid |
| 🔴 Lab coat | High | Misaligned & low quality | Invalid |
Humans have joints. False positives don’t.
Making Sure It’s Really a Human
Limitations of the original workflow
Previously:
Image → Object Detection → If “person” → VLM
The model classified anything that looked human-shaped as a person.
Real failing examples
Example: Chair backrest ≈ torso
Chair backrest → misread as head and torso
Chair legs → mistaken as human legs
→ Detected as sitting person ❌
Example: Coat on chair
Coat torso shape → detected as human body
Sleeves → detected as arms
→ VLM: “A staff member is working”
→ Reality: Just a chair ❌
Our revised approach: verify before you trust
[1] OD → Find potential humans
[2] Pose Estimation → Confirm real humans only
[3] VLM → High-level scene understanding
VitPose++ was selected due to its:
- Strong accuracy in diverse postures
- Lightweight small version enabling real-time inference
- Robust reliability in unpredictable on-site environments
Real-world Results
Before & After Comparison
Before: (OD only)
Detected: 28 persons
Actual: 15 persons
False Positive Rate: 46%
→ VLM: "28 people working"
After: (OD + Pose Estimation)
Detected = Actual: 15 persons
False Positive Rate: 0%
→ VLM: "15 people working"
No more chairs counted as humans. No more coats pretending to be employees.
Accuracy improved without performance loss
- Overall detection + verify → ~25ms/frame
- Real-time at 40 FPS
- Pose skipped when no humans detected
- Batch processing keeps latency low
Service Improvements
| Use Case | Problem Before | After |
|---|---|---|
| Office occupancy | Coats & chairs counted as humans | Accuracy jumped from 46% → 94% |
| Lab safety | “Ghost researchers” detected | Emergency response accuracy increased |
| Meeting room usage | Empty seats counted as attendees | True utilization tracked |
Accuracy up. GPU cost down. Trust level up.
Technical Highlights
A VLM’s performance is only as good as its input quality. By introducing a lightweight verification layer, we enabled:
- +35% VLM answer accuracy
- -20% processing time
- Massive drop in noisy detections
Small change, huge impact: A lightweight filter supercharges a heavyweight model.
Challenges & How We Overcame Them
| Challenge | Issue | Solution |
|---|---|---|
| Occlusion | Partial humans filtered out | Optimal threshold: ≥ 4 keypoints |
| Data bias | Clothes/chairs mistaken for humans | Keypoint confidence check |
| Performance | More models = slower? | VitPose-small + batch processing |
We turned real-world complexity into a reliable configuration.
Lessons Learned & What’s Next
“The real world is far simpler—and far more complex—than we expect.”
We learned that:
- Testing in real environments always matters more than theory
- The natural posture of humans is the strongest clue
- Real AI engineering is about designing the right pipeline, not stacking models
We’ll continue refining our system based on field insights and share more improvements along the way.
Conclusion
"An AI pipeline is only as strong as its weakest link."
Even top-tier VLMs fail when fed incorrect detections. By validating potential humans before VLM processing, we improved:
- Reliability
- Efficiency
- User trust
- Operational value
Not by adding more models, but by ensuring each component does the right job.

