TCR Features
Overview of Features
TCR Pipelines
AI Contents pipelines are composed of a combination of assets for different functionalities. The Train pipeline consists of 6 assets, while the Inference pipeline consists of 5.
Train Pipeline
Input - Readiness - Preprocess - Sampling - Train - Output
Inference Pipeline
Input - Readiness - Preprocess - Inference - Output
Input Asset
Reads files from the path specified in experimental_plan.yaml and converts them into dataframes.
Readiness Asset
Checks if the data provided is suitable for TCR modeling.
Preprocess Asset
Applies preprocessing methods such as categorical column encoding and missing value handling to the data for TCR modeling.
Sampling Asset
Applies oversampling or undersampling to balance the data if there is an imbalance in the labels.
Train Asset
Performs HPO using five built-in models and selects the best model to train.
Inference Asset
Uses the model created by the Train asset to infer the inference data.
Output Asset
Custom asset for modifying the output of the Train or Inference asset.
Usage Tips
Check Log Files After Running TCR in Auto Mode
After specifying the data path and X and Y columns in experimental_plan.yaml and running alo, TCR automatically inspects and preprocesses the input data. You can check the log file to verify the following items. The log file is located at 'train_artifacts/log/pipeline.log'. The image below shows an example log generated by the Readiness asset during TCR execution. The pipeline.log file contains the output logs for each asset.
# This is the result of running the readiness asset on the titanic dataset in TCR's sample_data/train_titanic.
...
[2024-04-09 01:53:46,045|USER|INFO|readiness.py(654)|save_info()] Pclass column is classified as numeric.
[2024-04-09 01:53:46,055|USER|WARNING|readiness.py(657)|save_warning()] Column Name exceeds the unique data limit of 50 and is excluded from x_columns.
[2024-04-09 01:53:46,063|USER|INFO|readiness.py(654)|save_info()] Sex column is classified as categorical.
[2024-04-09 01:53:46,072|USER|INFO|readiness.py(654)|save_info()] Age column is classified as numeric.
[2024-04-09 01:53:46,081|USER|INFO|readiness.py(654)|save_info()] SibSp column is classified as numeric.
[2024-04-09 01:53:46,089|USER|INFO|readiness.py(654)|save_info()] Parch column is classified as numeric.
[2024-04-09 01:53:46,099|USER|WARNING|readiness.py(657)|save_warning()] Column Ticket exceeds the unique data limit of 50 and is excluded from x_columns.
[2024-04-09 01:53:46,107|USER|INFO|readiness.py(654)|save_info()] Fare column is classified as numeric.
[2024-04-09 01:53:46,116|USER|WARNING|readiness.py(657)|save_warning()] Column Cabin exceeds the unique data limit of 50 and is excluded from x_columns.
[2024-04-09 01:53:46,126|USER|INFO|readiness.py(654)|save_info()] Embarked column is classified as categorical.
[2024-04-09 01:53:46,135|USER|INFO|readiness.py(654)|save_info()] Among the learning columns, ['Sex', 'Embarked'] are classified as categorical.
[2024-04-09 01:53:46,144|USER|INFO|readiness.py(654)|save_info()] Among the learning columns, ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare'] are classified as numeric.
[2024-04-09 01:53:46,153|USER|INFO|readiness.py(654)|save_info()] Survived column is classified as categorical.
...
- Check Column Type Classification in Readiness
- After running ALO, check if the x columns specified are correctly classified as numeric or categorical in the logs.
- If any columns are misclassified, use the readiness user argument column_types to manually specify the column types.
- Check Cardinality Test Results in Readiness
- TCR applies a cardinality condition (default: 50) to categorical columns. If the category count exceeds the cardinality condition, the column is excluded from x_columns. The log will indicate if any columns are excluded due to this condition.
- If the cardinality of your categorical data exceeds the default value of 50, adjust the cardinality argument in readiness.
Minimizing Memory Usage with Large Data
Using TCR can significantly increase memory usage, especially with large datasets due to categorical encoding preprocessing, data splitting for HPO, and oversampling. To reduce memory usage with large datasets, follow these settings:
- Preprocess: Change Categorical Encoding Method to catboost
- The default categorical encoding method is binary encoding. In the case of binary encoding, the number of categories does not increase significantly compared to onehot encoding, but if there are many categorical data and the cardinality is very high, the data size can increase. Therefore, by setting the user argument categorical_encoding to catboost encoding, you can prevent the increase in columns.
- Sampling Asset: Change Data Split Method to Train-Test Split
- The sampling asset creates datasets for HPO and splits data into train and validation sets.
- Cross-validation creates multiple copies of the data, increasing memory usage. Consider using train-test split instead.
Detailed Functionality
Train Pipeline: Input Asset
The Input asset reads all files from the specified user data path in experimental_plan.yaml and combines them into a single dataframe. The user data paths are specified in load_train_data_path and load_inference_data_path in experimental_plan.yaml. These should be folder paths, excluding the file names. The Train pipeline loads data from the load_train_data_path.
external_path:
- load_train_data_path: ./solution/sample_data/train
- load_inference_data_path: ./solution/sample_data/test
- save_train_artifacts_path:
- save_inference_artifacts_path:
- If the specified path contains subfolders, data from those subfolders will also be read and combined.
- All files in the specified path should have the same column names.
- For detailed descriptions of experimental_plan.yaml and input asset parameters, refer to the TCR Parameter Guide.
Train Pipeline: Readiness Asset
The Readiness asset checks if the data used for training/inference is suitable for TCR modeling. It performs necessary checks for both train and inference pipelines as detailed below.
Checks Performed
- Check if Columns Specified in experimental_plan.yaml Exist in Data
The readiness asset checks the following user arguments to ensure the specified column names exist in the dataframe. For detailed usage of each argument, refer to the TCR Parameter Guide.
- x_columns: Learning target columns
- y_column: Label column
- groupkey_columns: Columns used to group the dataframe by their values.
- drop_x_columns: Columns to exclude from learning target columns. Used when there are many columns to be included in x_columns.
The readiness asset supports the groupkey feature, which allows analysis by grouping data based on specific column values. For example, if a table contains a 'groupkey col' column, specifying it as the groupkey column will group data by its values (e.g., A, B). In this case, 'groupkey col' is the groupkey column, and A and B are the groupkeys. Use the groupkey_columns argument to enable this feature.
| x0 | ... | x10 | groupkey col |
|---|---|---|---|
| .. | .. | .. | A |
| .. | .. | .. | A |
| .. | .. | .. | B |
| .. | .. | .. | B |
| .. | .. | .. | A |
- Check Combinations of User Arguments
Checks for incompatible combinations of user arguments and stops the pipeline if errors are found.
- Errors if groupkey_columns is included in x_columns.
- Errors if y_column is included in x_columns.
- Errors if both x_columns and drop_x_columns contain values.
- Investigate Column Types of x Columns
The readiness asset determines if the x columns specified by the user are categorical or numeric using built-in logic. The readiness asset applies appropriate preprocessing methods to these columns in the next preprocess asset. The algorithm below shows how the readiness asset classifies column types. If any columns are misclassified, use the column_types user argument to specify their types. The 'Top N frequent value conversion' logic can be adjusted using the num_cat_split argument in the YAML file.
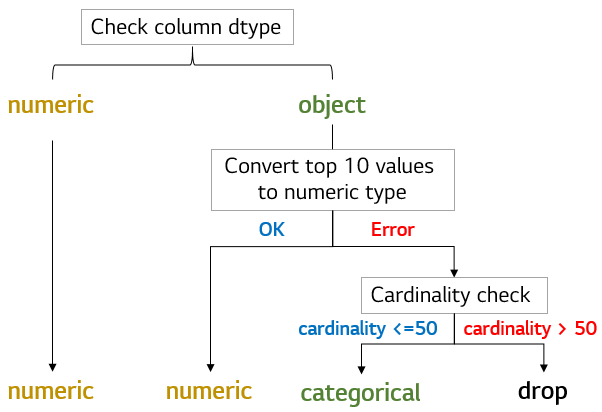
- Check Minimum Data Requirements for Training
The readiness asset ensures there are enough data points for training. If the data does not meet the minimum requirements, the asset raises an error to stop the pipeline. The default logic is as follows:
- For classification:
- Ensures at least 30 samples per label in the y column.
- For regression:
- Ensures at least 100 samples in total.
Use the min_rows user argument to modify the minimum data requirements.
<When Using the groupkey Feature> Minimum data requirements are checked per groupkey. If some groupkeys meet the requirements but others do not, the readiness asset proceeds with the groupkeys that meet the requirements and stops the pipeline if none do.
- Check if y Column Consists of a Single Value
The readiness asset raises an error if the y column consists of a single value since modeling is not possible in such cases.
- Check for Missing Values in x Columns
Columns in x_columns that are entirely composed of missing values are excluded from the learning target columns.
<When Using the groupkey Feature> If some groupkeys have x columns entirely composed of missing values, the following logic fills these missing values instead of deleting the column:
| x0 | ... | x10 | groupkey col |
|---|---|---|---|
| .. | .. | 1 | A |
| .. | .. | 2 | A |
| .. | .. | NaN | B |
| .. | .. | NaN | B |
| .. | .. | 2 | A |
- For categorical columns: fills with the most frequent value in x10 for groupkey B.
- For numeric columns: fills with the median value in x10 for groupkey B.
- Check for Consistent y Column Classes Across Groupkeys
When using groupkeys, all groupkeys must have the same set of y column classes. Groupkeys not meeting this condition are excluded from the learning targets.
Train Pipeline: Preprocess Asset
The Preprocess asset applies data type conversion and preprocessing methods to the training data. It handles the following four preprocessing tasks:
- Missing Value Handling (handle_missing argument)
- For categorical columns: frequent (fill with the most frequent value)
- For numeric columns: mean, median, interpolation
- For all columns: drop (remove rows with missing values), fill_{value} (fill missing values with {value})
- Categorical Encoding (categorical_encoding argument)
- binary, catboost, onehot, label encoding
- Numeric Data Scaling (numeric_scaler argument)
- Standard, minmax, robust, maxabs, normalizer
- Numeric Data Outlier Removal (numeric_outlier argument)
- Normal (removes outliers beyond 3 sigma of the current data distribution)
The Preprocess asset applies default rules to the x and y columns classified by the readiness asset. The default preprocessing rules are as follows:
<Default Preprocessing for x Columns>
- Missing Value Handling
- Fills categorical columns with the most frequent value (frequent).
- Fills numeric columns with the median value (median).
- Categorical Encoding
- Applies binary encoding.
<Default Preprocessing for y Columns>
- Missing Value Handling
- Removes rows with missing values (drop). (Cannot be changed by user arguments)
- Categorical Encoding
- Applies label encoding for classification tasks (cannot be changed by user arguments).
The default logic for x columns can be modified by adding arguments to the YAML file. For detailed instructions, refer to the TCR Parameter Guide.
Train Pipeline: Sampling Asset
The Sampling asset has two main functions: data split for HPO and handling imbalanced data.
- Data Split
The sampling asset creates datasets for HPO and splits data into train and validation sets. The methods available are cross-validation and train-test split, which can be changed using the data_split argument in the YAML file.
-
Cross-Validation
- Uses cross-validation to split data into train and validation sets.
- The default setting in the YAML file is cross-validation with 3 folds.
- Creates and passes data to the next asset in the format
[[train_fold1, validation_fold1], [train_fold2, validation_fold2], ...]. - If both data split and sampling methods are used, sampling is applied to each fold's train set.
- Data is duplicated for each fold, increasing memory usage. Consider this when selecting the number of folds.
-
Train-Test Split
- Splits data into train and validation sets based on a specified ratio.
- If both data split and sampling methods are used, sampling is applied to the train set.
- Passes data to the next asset in the format
[[train set, validation set]].
- Sampling
Applies oversampling or undersampling based on specific label criteria. You can select the label to sample and specify the sampling ratio.
- Oversampling
- Methods: random, smote
- For usage, refer to the over_sampling argument.
- Undersampling
- Methods: random, nearmiss
- For usage, refer to the under_sampling argument.
Train Pipeline: Train Asset
The Train/Inference assets in TCR include five built-in models. These models, along with their parameter sets, were selected based on data analysts' frequent use for classification/regression tasks. The models and their parameter sets are listed below.
Built-in TCR Models
- rf: Random Forest
- (max_depth: 6, n_estimators: 300), (max_depth: 6, n_estimators: 500)
- gbm: Gradient Boosting Machine
- (max_depth: 5, n_estimators: 300), (max_depth: 6, n_estimators: 400), (max_depth: 7, n_estimators: 500)
- lgbm: Light Gradient Boosting Machine
- (max_depth: 5, n_estimators: 300), (max_depth: 7, n_estimators: 400), (max_depth: 9, n_estimators: 500)
- cb: CatBoost
- (max_depth: 5, n_estimators: 100), (max_depth: 7, n_estimators: 300), (max_depth: 9, n_estimators: 500)
- xgb: Extreme Gradient Boosting
- (max_depth: 5, n_estimators: 300), (max_depth: 6, n_estimators: 400), (max_depth: 7, n_estimators: 500)
Adding New Models
To add new models to TCR, refer to the code below and create the desired model file. Place the created model file in TCR's model file path, and you can easily perform HPO with the new model along with the built-in TCR models. We recommend adding models provided by Scikit-learn as they include the necessary fit, load, and predict functions. Below is the code for the Random Forest model file in TCR.
< TCR Basic Model: Random Forest (rf.py) >
from sklearn.ensemble import RandomForestClassifier # Import model
from .classifier import Classfier
# Set default parameters. Refer to the parameter documentation for the desired model.
DEFAULT_PARAM = {
'max_depth': 6,
'n_estimators': [300, 500],
'random_state': 1234,
'n_jobs': 1,
'tcr_param_mix': 'one_to_one',
}
class TCR_model(Classfier):
def __init__(self, model_name, model_type, param_dict):
model = RandomForestClassifier(**param_dict) # Call the imported model
super().__init__(model_name, model_type, model)
Below is an example of creating a decision tree model file based on the rf.py code.
<Decision Tree Model File (dt.py)>
from sklearn.tree import DecisionTreeClassifier # (1) Import model
from .classifier import Classfier
DEFAULT_PARAM = { # (2) Modify DEFAULT_PARAM with parameters provided by DecisionTreeClassifier
'max_depth': [3, 6],
'min_samples_split': [2, 3],
'tcr_param_mix': 'one_to_one'
}
class TCR_model(Classfier):
def __init__(self, model_name, model_type, param_dict):
model = DecisionTreeClassifier(**param_dict) # (3) Modify model call
super().__init__(model_name, model_type, model)
Follow these steps to create and add a model file:
- Copy the code above to create a 'model_name.py' file.
- Modify the import statement to import the desired model.
- Modify DEFAULT_PARAM with parameters provided by the model.
- Refer to the model library's documentation for parameters and specify the search range for HPO.
- Each parameter can be a single
value or a list of values.
- Set 'tcr_param_mix': 'one_to_one' to create parameter pairs with elements in the same position in the lists. For example, for max_depth and min_samples_split parameters, the pairs (3,2) and (6,3) will be created.
- Set 'tcr_param_mix': 'all' to create parameter pairs with all combinations of elements in the lists. For example, for max_depth and min_samples_split parameters, the pairs (3,2), (6,2), (3,3), and (6,3) will be created.
- Modify the class TCR_model to call the imported model.
- Assign the model to the model variable.
- Implement the fit, load, and predict functions if necessary (not needed for Scikit-learn models).
- Place 'model_name.py' in the following path:
- To access TCR code, run TCR once. This will download the asset codes under alo/assets/.
- For classification models, place the file in alo/assets/train/src_tcr/classification_model/.
- For regression models, place the file in alo/assets/train/src_tcr/regression_model/.
- Add the model_name to the model_list argument in experimental_plan.yaml and run alo.
- For example, model_list: [model_name], model_list: [model_name, rf] (runs both model_name and built-in rf).
HPO Functionality
TCR's HPO process is as follows:
- Data Splitting for HPO
- Splits data into train and validation sets using cross-validation or random sampling. The default is 5-fold cross-validation, configurable via the data_split argument.
- Comparing Candidate Models Based on Evaluation Metrics
- The default evaluation metric is accuracy for classification and mse for regression. Use the evaluation_metric argument to specify a different metric.
- To weight evaluation metrics for specific labels, use the target_label argument in the readiness asset. For example, if correctly predicting NG data is important, set target_label to NG and evaluation_metric to recall. The model with the highest recall for the NG class will be selected as the best model and parameter set.
- If multiple models have the same evaluation_metric value during the HPO process, the priority of the models will be determined in the following order.
- When the evaluation_metric values are the same:
- For classification, compare the other metrics in the order of accuracy, f1, recall, and precision (if accuracy is selected, compare values in the order of f1, recall, and precision).
- For regression, compare the other metrics in the order of r2, mse, mae, and rmse.
- When all evaluation metric values are the same:
- The smaller the model size, the higher the priority. If model sizes are similar, they will be sorted in the order of rf, lgbm, gbm, xgb, and cb models.
- However, if all evaluation metric values are the same and the user has manually added a model, the user-added model will have the highest priority.
- Re-training the Best Model with the Entire Dataset
- Since the model only uses part of the data for training during HPO (excluding the validation set), the best model is re-trained with the entire dataset.
TCR allows various HPO modeling experiments by modifying/adding user arguments. The following arguments are related to modeling:
- evaluation_metric
- Specifies the evaluation metric for HPO.
- model_list
- Selects specific models for HPO.
- data_split
- Specifies the data split method for HPO.
- hpo_settings
- Specifies the parameter sets for each model.
Providing XAI Functionality
TCR provides the ability to calculate Shapley values to understand how specific variables in the data affect the y value. Set the shapley_value argument to True to include Shapley values for each learning column in the output.csv file.
Inference Pipeline: Input Asset
Functions the same as in the Train pipeline, loading data from the load_train_data_path for the Inference pipeline.
Inference Pipeline: Readiness Asset
Checks Performed
- Checking for Categorical Data During Inference
If x columns used during training contain categorical columns, the preprocess asset applies categorical encoding. If new values not seen during training appear in these columns during inference, encoding will fail, and the readiness asset will raise an error to stop the pipeline. This default behavior can be changed by adding the ignore_new_category argument to the YAML file.
By adding 'ignore_new_category: True' to the YAML file, any category data not used in training will be treated as missing, and the inference results will still be output.
- Checking for New groupkey Values During Inference (When Using groupkey Feature) If new groupkey values not used during training appear during inference, the readiness asset will exclude these groupkeys from the inference targets.
Inference Pipeline: Preprocess Asset
Loads the scikit-learn-based preprocessing models created by the preprocess asset in the Train pipeline and applies preprocessing to the inference data.
Inference Pipeline: Inference Asset
Uses the model trained by the Train asset to infer the inference data.
TCR Version: 2.1.1