Multi-Frame Based VLM Detection: Moving Beyond Single Image Limits to Temporal Context




Is a Single Frame Enough?
Recently, Vision-Language Models (VLMs) have demonstrated exceptional performance in understanding individual images. Large-scale multimodal models have theoretically expanded the possibilities of multi-frame reasoning by introducing architectures that process multiple images alongside text prompts.
However, real-world industrial detection scenarios are far more complex than controlled research environments. Problems that seem straightforward with a single frame often lead to various false positives and edge cases in production.
Consider a scene where a person is lying on the floor. Looking at that single moment, it is easy to categorize it as a "collapse." But what if the previous frame showed them stretching, or simply changing posture while working?
In nighttime environments, lens flares, light reflections, or glare can mimic the color patterns of fire, leading to false fire detections when based on a single image. When even humans find it difficult to be certain from a single snapshot, providing a model with only one frame inevitably creates structural limitations.

These cases all share a common problem: a "lack of context."
Time is the Most Powerful Context
Many detection scenarios inherently rely on a temporal flow.
For instance, "loitering" can only be defined by observing a pattern of staying in the same space for a certain period. Similarly, "long-term abandonment" requires the condition that an object remains unchanged for a specific duration after being placed.
Attempting to solve these problems with a single frame is structurally difficult because the focus must be on "change," not just "state."
We have categorized this into three levels of context:
- Single Image-based Judgment
- Short-term Multi-image Contextual Judgment (Momentary context)
- Temporal Judgment (Involving long-term flow)
In actual operating environments, these three levels coexist. Some scenarios are sufficient with a single frame, some require consecutive frames at intervals of a few seconds, and others require tracking a flow over tens of seconds.
EVA's Multi Frame Manager
In EVA, user-defined scenarios are not treated as simple text conditions. The system analyzes the "level of context" required by each scenario and determines an appropriate frame collection strategy.
For example, "fainting detection" requires multi-images covering a few seconds before and after the event, rather than a single frame. In contrast, "long-term abandonment" requires continuous frame collection over a specific duration based on a sliding window.
The module responsible for this process is the Multi Frame Manager. This module dynamically determines the following based on the scenario characteristics:
- Number of frames required
- Collection intervals
- Retention time
- Event trigger expansion
Collected images are not simply listed. They are delivered to the VLM in a clearly sorted chronological order, accompanied by system prompts that guide the model to compare changes between frames.
Multi-Image Based VLM Inference Strategy
When multi-frame input is received, the VLM does more than just return independent detection results. In EVA, we designed the inference structure to interpret multi-images as a continuous temporal context rather than an independent set of images.
To achieve this, frames are delivered to the model using the following strategies:
- Chronological Frame Alignment: Constructs time-series data from past to present to understand causality.
- Comparative System Prompts: Uses instructions like "Identify changes compared to the previous frame" to analyze inter-frame correlations.
- Temporal Reasoning: Derives logical conclusions based on state changes over time rather than fragmented snapshot judgments.
Case Study: The Power of Temporal Context in Reducing False Positives
The following case demonstrates how fragmented information from a single frame is accurately corrected through the "context" of multiple frames.
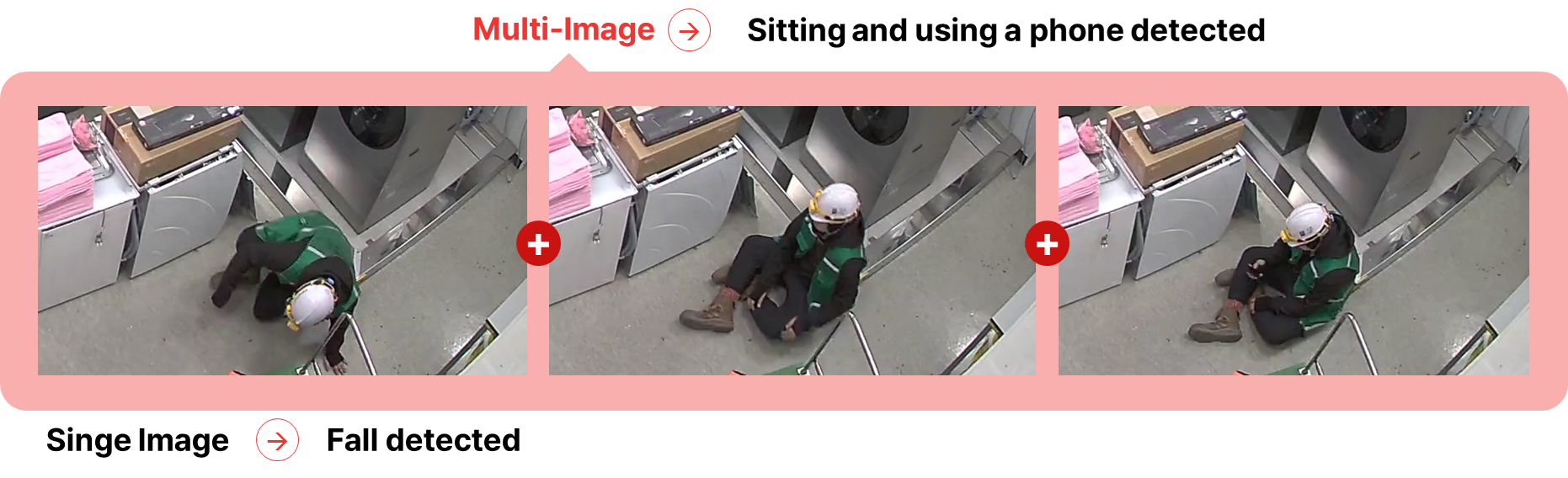
- Single Image: A person is stationary in a low, prone position. A VLM looking only at this moment is highly likely to misinterpret the situation as "Collapse."
- Multi-Image: In the subsequent frames, subtle movements are captured—the person moves their arms to operate a phone and tilts their head to look at the screen.
- Result: Through Temporal Reasoning, EVA correctly concludes this is "Sitting and using a phone detected".
The core idea is to guide the model to understand the situation by comparing differences between frames, rather than judging each frame individually.
For high-risk detections like fainting, the model undergoes a process of Progressive Situation Refinement:
- Initial State Identification: Identifying the target object and initial visual features (e.g., prone posture).
- Dynamic Change Detection: Tracking meaningful changes in body angles or voluntary movements compared to previous frames.
- Consistency Verification: Determining if the posture is a forced freeze due to impact or involves intentional actions.
- Final Context Determination: Distinguishing between visual noise with similar patterns and actual events.
This Temporal Reasoning structure significantly reduces false positives in edge cases that plague single-image systems, providing much more stable results in real-world operations.
| Category | Single Image | Multi Image | ||||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | Accuracy | Precision | Recall | |
| No PPE | 0.66 | 0.87 | 0.68 | 0.76 | 0.87 | 0.82 |
| No Mask (Working) | 0.94 | 0.69 | 0.54 | 0.93 | 0.76 | 0.52 |
| Loitering | 0.49 | 0.92 | 0.33 | 0.63 | 0.85 | 0.64 |
| Fainting | 0.87 | 1.0 | 0.36 | 0.96 | 1.0 | 0.82 |
Ultimately, EVA’s multi-frame inference structure is not just about increasing the number of input images—it is an approach that directly integrates temporal change into the model's reasoning process.
The Cost of Multi-Frame: Computational Overload
Improvements in accuracy come with a price.
While multi-frame reasoning allows for more visual information, it also leads to increased computational costs. In multimodal models, image inputs are generally converted into embeddings via a Vision Encoder before being passed to the LLM, a process that is relatively resource-intensive.
Specifically, multi-frame analysis often encounters the following:
- Identical or very similar images repeating in a sequence.
- Multiple requests referencing the same camera frame.
- Multiple queries performed on the same set of images.
In these cases, if the Vision Encoder processes the same image repeatedly, it creates unnecessary overhead.
In EVA, we developed a structure that maximizes the Encoder Cache feature provided by vLLM to solve this. vLLM offers an Encoder Cache Manager that allows the system to cache and reuse Vision Encoder results during multimodal processing.
By leveraging this, we can reuse previously generated encoder embeddings for identical image inputs, eliminating the need to repeat Vision Encoder operations. EVA applies a request management structure at the Agent Layer to effectively utilize this caching.
The Agent coordinates requests in the following ways:
- Organizing requests so that identical image inputs can be reused.
- Managing requests based on image units to enable cache hits.
- Optimizing request flow to prevent redundant encoding.
This allows us to minimize Vision Encoder operations and utilize GPU resources more efficiently, even in a multi-frame analysis environment.
Conclusion
Multi-frame based VLM inference is an approach that significantly improves situational understanding and detection accuracy compared to single-image analysis.
However, as the number of frames increases, the computational load on the Vision Encoder grows significantly. Therefore, it is crucial to design a system that balances performance gains with computational efficiency and infrastructure costs.
EVA addresses this by actively utilizing vLLM's Encoder Cache and managing requests through the Agent Layer. Through this architecture, we maintain high inference performance while reducing unnecessary computations, continuously improving GPU efficiency and infrastructure operating costs.
This feature is available starting from EVA v2.6.0.

